POINT1. 옵티마이저(Optimizer)와 실행 계획
- 옵티마이저(Optimizer)
- SQL개발자가 SQL을 작성하여 실행할 때, 옵티마이저는 SQL을 어떻게 실행할 것인지를 계획하게 된다. 즉, SQL 실행 계획(Execution Plan)을 수립하고 SQL을 실행한다.
- 옵티마이저는 SQL의 실행 계획을 수립하고 SQL을 실행하는 DBMS 이다.
- 동일한 결과가 나오는 SQL도 어떻게 실행하느냐에 따라서 성능이 달라진다.
- 따라서 옵티마이저의 실행 계획은 SQL 성능에 아주 중요한 역할을 한다.
- 옵티마이저 특징
- 옵티마이저는 데이터 딕셔너리에 있는 오브젝트통계, 시스템통계 등의 정보를 사용해서 예상되는 비용을 산정한다.
- 옵티마이저는 여러 개의 실행 계획 중에서 최저비용을 가지고 있는 계획을 선택해서 sql을 실행한다.
- 옵티마이저의 필요성
- SQL 개발자가 작성한 SQL문을 어떻게 실행하느냐에 따라 성능이 달라진다.

- 위의 예를 보면 먼저 EMP테이블을 실행하고 EMP테이블에서 찾은 행과 동일한 것을 DEPT테이블에서 찾는다. 그리고 최종 결과집합을 인출한다.
- 앞의 예를 보면 건수가 많은 EMP 테이블을 먼저 읽고 DEPT 테이블을 읽으면 불필요하게 비교 횟수가 증가하게 된다. 만약, DEPT테이블을 먼저 읽고 EMP 테이블을 읽게 되면 비교 횟수를 줄일 수 있다.
- 본 SQL문은 AND 조거이므로 작은 집합을 먼저 읽어도 큰 집합을 먼저 읽는 것과 동일한 결과가 나오게 된다.
- 옵티마이저는 이러한 실행 계획을 수립하는 것이며, 만약 옵티마이저가 비효율적으로 실행 계획을 수립하면 SQL개발자는 SQL을 개선해야 한다. 이때 옵티마이저에게 실행 계획을 변경하도록 요청할 수가 있는데 이때 힌트(HINT)를 사용한다.
- 옵티마이저 실행 계획 확인
- 옵티마이저는 SQL 실행 계획을 PLAN_TABLE 에 저장한다.
- 그래서 SQL개발자는 PLAN_TABLE 을 조회해서 실행 계획을 확인할 수 있다.
EX) 1 DESC PLAN_TABLE;
- 가장 편리하게 실행 계획을 확인하는 방법은 TOAD에서 Execution Plan Current SQL 메뉴를 클릭하면 된다.
POINT2. 옵티마이저 종류
- 옵티마이저의 실행 방법
- 개발자가 SQL을 실행하면 파싱(Parsing)을 실행해서 SQL의 문법 검사 및 구문 분석을 수행한다.
- 구문분석이 완료되면 옵티마이저가 규칙 기반 혹은 비용 기반으로 실행 계획을 수립한다.
- 옵티마이저는 기본적으로 비용 기반 옵티마이저를 사용해서 실행 계획을 수립한다. 비용 기반 옵티마이저는 통계 정보를 활용해서 최적의 실행 계획을 수립하는 것이다.
- 실행 계획이 수립되면 최종적으로 sql을 실행하고 실행이 완료되면 데이터를 인출(Fetch) 한다.
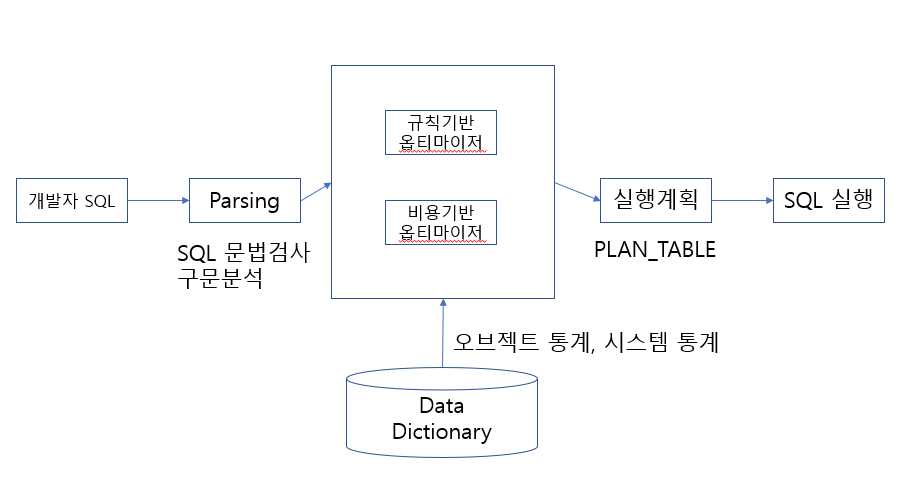
옵티마이저 엔진
| 옵티마이저 | 설명 |
| Query Transfomer | - SQL문을 효율적으로 실행하기 위해서 옵티마이저가 변환한다. - SQL이 변환되어도 그 결과는 동일하다. |
| Estimator | - 통계정보를 사용해서 SQL 실행 비용을 계산한다. - 총비용은 최적의 실행 계획을 수립하기 위해서이다. |
| Plan Generator | SQL을 실행할 실행 계획을 수립한다. |
- 옵티마이저 엔진
- 규칙 기반 옵티마이저는 실행 계획을 수립할 때 15개의 우선순위를 기준으로 실행 계획을 수립한다.
- 최신 Oracle 버전은 규칙 기반 옵티마이저 보다 비용 기반 옵티마이저를 기본적으로 사용한다.

- 위의 SQL 문은 '/*+ RULE */' 를 사용해서 옵티마이저에서 규칙 기반 옵티마이저로 실행하도록 알려주었다. 이렇게 옵티마이저에서 실행방법을 알려주는 것이 힌트(HINT) 이다.
- 실행 계획을 확인한 결과 EMP 테이블을 ROWID 로 조회했다.
- 비용 기반 옵티마이저
- 비용 기반 옵티마이저는 오브젝트 통계 및 시스템 통계 를 사용해서 총 비용을 계산한다.
- 총비용이라는 것은 SQL문을 실행하기 위해서 예상되는 소요시간 혹은 자원의 사용량을 의미한다.
- 총비용이 적은 쪽으로 실행 계획을 수립한다. 단, 비용 기반 옵티마이저에서 통계정보가 부적절한 경우 성능 저하가 발생할 수 있다.
POINT3. 인덱스
- 인덱스(Index)
- 인덱스는 데이터를 빠르게 검색할 수 있는 방법을 제공한다.
- 인덱스는 인덱스 키로 정렬 되어 있기 때문에 원하는 데이터를 빠르게 조회한다.
- 인덱스는 오름차순 및 내림차순 탐색이 가능하다.
- 하나의 테이블에 여러 개의 인덱스를 생성할 수 있고 하나의 인덱스는 여러 개의 칼럼으로 구성될 수 있다.
- 테이블을 생성할 때 기본키는 자동으로 인덱스가 만들어지고 인덱스의 이름은 SYSXXXX 이다.

- 인덱스의 구조는 Root Block, Branch Block, Leaf Block 으로 구성되고 Root Block은 인덱스 트리에서 가장 상위에 있는 노드를 의미하며, Branch Block 은 다음 단계의 주소를 가지고 있는 포인터로 되어있다.
- Leaf Block 은 인덱스 키와 ROWID로 구성되고 인덱스 키는 정렬되어 저장되어 있다.
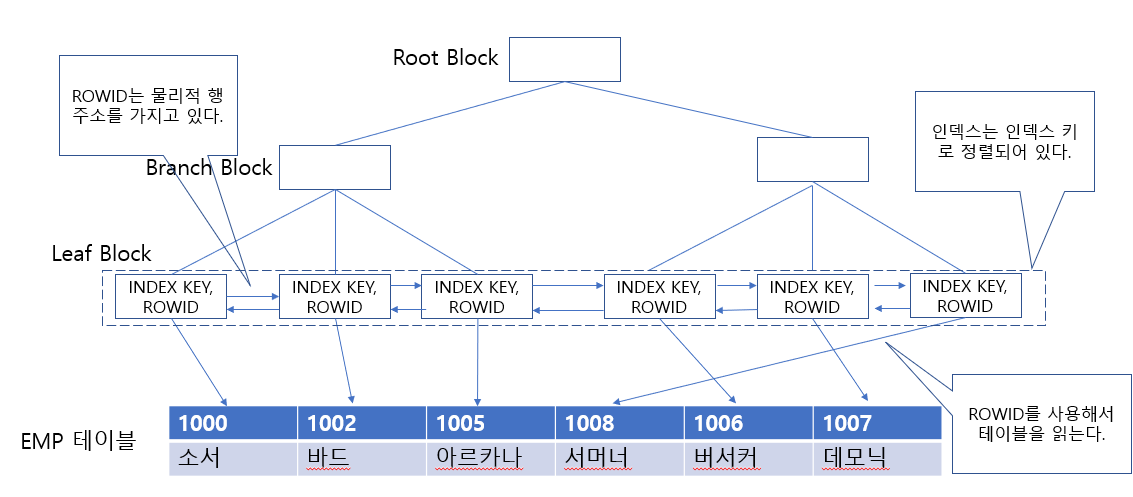
- 위의 예는 인덱스를 스캔하고 테이블을 참조하는 것을 설명하고 있다.
- Leaf Block은 Double Linked List 형태로 되어 있어서 양방향 탐색이 가능하다.
- Leaf Block에서 인덱스 키를 읽으면 ROWID를 사용해서 EMP 테이블의 행을 직접 읽을 수 있다.
- 인덱스 생성
- 인덱스 생성은 "CREATE INDEX" 문을 사용해서 생성이 가능하다.
- 인덱스를 생성할 때는 한 개 이상의 칼럼을 사용해서 생성할 수 있다.
- 인덱스 키는 기본적으로 오름차순으로 정렬하고 "DESC" 구를 포함하면 내림차순으로 정렬한다.

- 위의 예는 ename 에 대해서 오름차순으로 정렬하고 sal 은 내림차순으로 정렬하는 인덱스를 생성한다. 여기서 ename 에 "asc" 구는 생략이 가능하다.
- 인덱스 스캔 (Index Scan)
- 인덱스 유일 스캔 (Index Unique SCAN)
- Index Unique SCAN 은 인덱스 키 값이 중복되지 않는 경우, 해당 인덱스를 사용할 때 발생 된다.
- 예를 들어 EMPNO(사원번호)가 중복되지 않는 경우 특정 하나의 EMPNO를 조회한다.
- 인덱스 범위 스캔 (Index Range SCAN)
- Index Range SCAN은 SELECT 문에서 특정 범위를 조회하는 WHERE 문을 사용할 경우 발생한다.
- Like, Between 이 그 대표적인 예이다. 물론, 데이터 양이 적은 경우는 인덱스 자체를 실행하지 않고 TABLE FULL SCAN 이 될 수 있다.
- Index Range SCAN 은 인덱스의 Leaf Block 의 특정 범위를 스캔한 것이다.
- 인덱스 전체 스캔 (Index Full SCAN)
- Index Full SCAN 은 인덱스에서 검색되는 인덱스 키가 많은 경우에 Leaf Block 의 처음부터 끝까지 전체를 읽어 들인다.
High Watermark
- 테이블을 읽을 때 high watermark 이하까지만 table full scan 을 한다.
- high watermark 는 테이블에 데이터가 저장된 블록에서 최상위 위치를 의미하고 데이터가 삭제되면 high watermark 가 변경된다.
POINT4. 실행계획 (Execution Plan)
- 실행 계획을 읽는 방법은 옆에 나와있는 번호 순서대로 읽으면 된다.
- 이때, 먼저 조호되는 테이블을 Outer Table 이라고 하고 그 다음에 조회되는 테이블을 Inner Table 이라고 한다.
POINT5. 옵티마이저 조인 (Optimizer Join)
- Nested Loop 조인
- Nested Loop 조인은 하나의 테이블에서 데이터를 먼저 찾고 그 다음 테이블을 조인하는 방식으로 실행된다.
- Nested Loop 조인에서 먼저 조회되는 테이블을 외부 테이블(Outer Table) 이라고 하고 그 다음 조회되는 테이블을 내부 테이블(Inner Table) 이라고 한다.
- Nested Loop 조인은 RANDOM ACCESS 가 발생하는데 RANDOM ACCESS가 많이 발생하면 성능 지연이 발생한다.
그러므로 Nested Loop 조인은 RANDOM ACCESS의 양을 줄여야 성능이 향상된다.
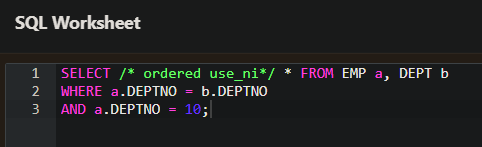
- 위의 예는 use_nl 힌트를 사용해서 의도적으로 Nested Loop 조인을 실행했다.
- ordered 힌트는 FROM 절에 나오는 테이블 순서대로 조인을 하게 하는 것이다. ordered 힌트는 혼자 사용되지 않고 use_nl, use_merge, use_hash 힌트와 함께 사용된다.
- 실행 계획을 보면 EMP테이블을 먼저 FULL SCAN 하고 그 다음 DEPT 테이블을 FULL SCAN 하여 Nested Loop 조인을 하는 것이다.
- Sort Merge 조인
- Sort Merge 조인은 두 개의 테이블을 SORT_AREA 라는 메모리 공간에 모두 로딩하고 SORT를 수행한다.
- 두 개의 테이블에 대해서 SORT 가 완료되면 두 개의 테이블을 병합(Merge) 한다.
- Sort Merge 조인은 정렬(sort)이 발생하기 때문에 데이터양이 많아지면 성능이 떨어지게 된다.
- 정렬 데이터양이 너무 많으면 정렬은 임시 영역에서 수행된다. 임시 영역은 디스크에 있기 때문에 성능이 급격히 떨어진다.
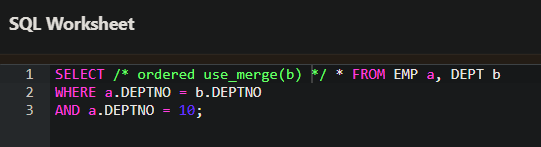
- use_merge 힌트를 사용해서 SORT MERGE 조인을 할 수 있다.
- Hash 조인
- Hash 조인은 두 개의 테이블 중에서 작은 테이블을 HASH 메모리에 로딩하고 두 개의 테이블의 조인 키를 사용해서 해시 테이블을 생성한다.
- Hash 조인은 해시 함수를 사용해서 주소를 계산하고 해당 주소를 사용해서 테이블을 조인하기 때문에 CPU 연산을 많이 한다.
SQL 최적화의 원리 확인문제
1. 다음 중에서 SQL 실행 계획을 수립하는 것은?
① 데이터 딕셔너리
② 옵티마이저
③ Query Transformer
④ SQL 엔진
내가 고른 답 : 2
정답 : 2
해설 : 옵티마이저는 SQL문에 대해서 실행 계획을 수립한다.
2. 다음 중에서 인덱스 트리 구조가 아닌 것은?
① Root
② Branch
③ Double
④ Leaf
내가 고른 답 : 3
정답 : 3
해설 : 인덱스 트리구조는 Root Block, Branch Block, Leaf Block 으로 구성된다.
3. 다음 중에서 Random Access가 가장 많이 발생하는 것은?
① Nested Loop
② Sort Merge
③ Hash
④ Inner join
내가 고른 답 : 1
정답 : 1
해설 : Nested Loop 조인은 중첩된 for문의 구조로 선행 테이블이 후행 테이블 조인 시에 Random Access가 발생한다.
4. 다음 중에서 SORT 가 가장 많이 발생하는 것은?
① Nested Loop
② Sort Merge
③ Hash
④ Inner join
내가 고른 답 : 2
정답 : 2
해설 : SORT MERGE 는 두 개의 테이블을 SORT 한 후에 MERGE 하는 방식으로 실행되기 때문에 SORT 가 많이 발생한다.
5. 다음 중 테이블에서 데이터가 저장되어있는 최상위 위치는?
① High Watermark
② Top
③ ROWID
④ MAX Extents
내가 고른 답 : 1
정답 : 1
해설 : High Watermark는 테이블에서 데이터가 저장되어있는 최상위 위치를 의미한다.
6. 다음은 test라는 파티션 테이블을 생성하는 SQL문이다. test_idx 인덱스의 종류로 올바른 것은?
CREATE TABLE test (a number, b char(3) c varchar2(10) )
PARTITION BY RANGE(a) (
PARTITION p1 VALUES LESS THAN(1000),
PARTITION p2 VALUES LESS THAN(2000),
PARTITION p3 VALUES LESS THAN(maxvalue)
CREATE INDEX test_idx on test(b) LOCAL;
① Global Prefixed Partition Index
② Global Non-Prefixed Partition Index
③ Local Prefixed Partition Index
④ Local Non-Prefixed Partition Index
내가 고른 답 : 4
정답 : 4
해설 : 인덱스를 생성할 때 local 키워드를 사용했으므로 local 인덱스이다. 그리고 test 테이블을 생성할 때 range 파티션 키가 a이고 인덱스는 b로 생성했다. 그러므로 non-prefixed 인덱스이다.
global index - 여러 개의 파티션에서 하나의 인덱스를 사용한다.
local index - 해당 파티션 별로 각자의 인덱스를 사용한다.
prefixed index - 파티션 키와 인덱스 키가 동일하다.
non-prefixed index - 파티션 키와 인덱스 키가 다르다.
7. FROM절에 기술한 테이블 순서대로 조인을 하는 힌트(Oracle)는 무엇인지 작성하시오.
내가 고른 답 : ordered
정답 : ORDERED
해설 : oracle db는 ordered 힌트이고 ms-sql은 option(force order) 이다.
시험 3일남음 ㅅㅂ
'파이썬 > SQLD' 카테고리의 다른 글
| [SQLD] 시험준비 4주 3일차 - 실전모의고사 150문제 오답노트 (0) | 2022.05.26 |
|---|---|
| [SQLD] 시험준비 4주 2일차 3 - SQL 기본 및 활용 단원정리문제 (0) | 2022.05.25 |
| [SQLD] 시험준비 4주 2일차 1 - SQL 활용 확인문제 (0) | 2022.05.24 |
| [SQLD] 시험준비 4주 1일차 - SQL 활용2 (0) | 2022.05.23 |
| [SQLD] 시험준비 3주 5일차 - SQL 활용 (0) | 2022.05.22 |