
2일안에 남은 진도를 모두 빼고
빨리 기출문제를 푸는 단계로 넘어가자
시험 5일남았다
SECTION02 SQL 활용
POINT1 조인(Join)
- EQUI(등가) 조인(교집합)
EQUI(등가) 조인
- 조인은 여러 개의 릴레이션을 사용해서 새로운 릴레이션을 만드는 과정이다.
- 조인의 가장 기본은 교집합을 만드는 것이다.
- 두 개의 테이블 간에 일치하는 것을 조인한다.

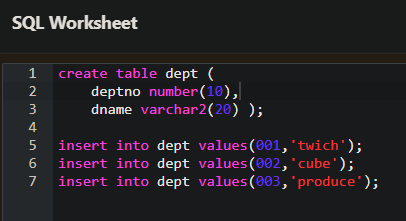
- EQUI 조인은 EMP 테이블과 DEPT 테이블에서 DEPTNO 칼럼을 사용하여 같은 것을 조인한다.
- 위의 예를 보면 EMP 테이블의 DEPTNO 와 DEPT 테이블의 DEPTNO 가 같은 것을 사용하여 조인한다.
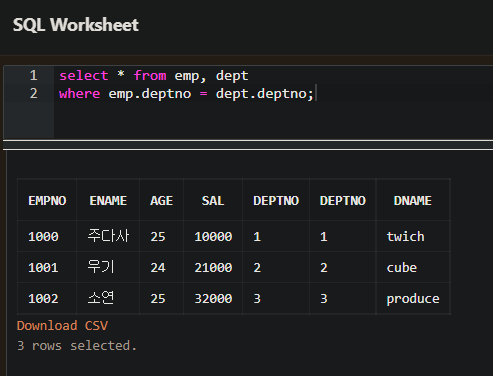
- EQUI 조인은 = 를 이용해서 두개의 테이블을 연결한다.
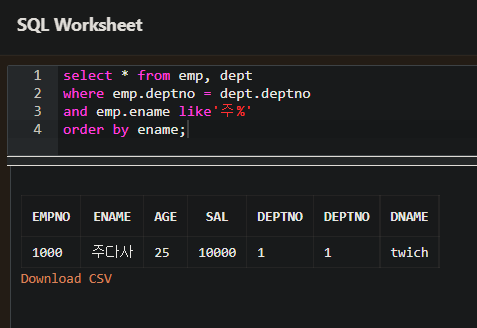
INNER JOIN
- EQUI 조인과 마찬가지로 ISO 표준 SQL 로 INNER JOIN 이 있다. INNER JOIN 은 ON 문을 사용해서 테이블을 연결한다.
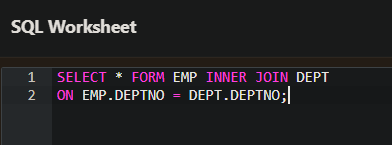
- 위 예를 보면 INNER JOIN 구에 두 개의 테이블명을 서술하고 ON구로 조인 조건을 서술한다.
- EQUI 조인을 한 후에 실행 계획을 확인해서 내부적으로 두 개의 테이블을 어떻게 연결했는지 확인할 수 있다.
- 해시 함수는 테이블을 해시 메모리에 적재한 후에 해시 함수로써 연결하는 방법이다.
- 해시 조인은 EQUI 조인만 사용 가능한 방법이다.
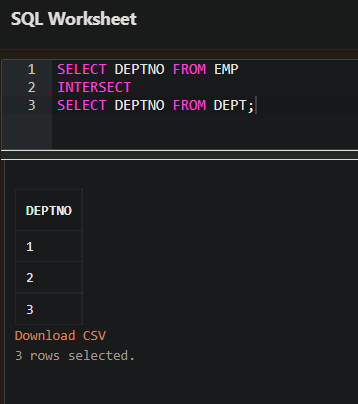
INTERSECT 연산
- INTERSECT 연산은 두 개의 테이블에서 교집합을 조회한다.
- 즉, 두 개 테이블에서 공통된 값을 조회한다.
- Non-EQUI(비등가) 조인
- Non-EQUI 는 두 개의 테이블 간에 조인하는 경우 '=' 를 사용하지 않고 '>' '<' '>=' '<=' 등을 사용한다
- 즉, Non-EQUI 조인은 정확하게 일치하지 않는 것을 조인하는 것이다.
- OUTER JOIN
- OUTER JOIN 은 두 개의 테이블 간에 교집합(EQUI JOIN)을 조회하고 한쪽 테이블에만 있는 데이터도 포함시켜서 조회한다.
- 예를 들어 DEPT 테이블과 EMP 테이블을 OUTER JOIN 하면 DEPTNO 가 같은 것을 조회하고 DEPT 테이블에만 있는 DPTNO도 포함시킨다.
- 이때 왼쪽 테이블에만 있는 행도 포함하면 LEFT OUTER JOIN 이라고 하고 오른쪽 테이블의 행만 포함시키면 RIGHT OUTER JOIN 이라고 한다.
- FULL OUTER JOIN 은 LEFT OUTER JOIN 과 RIGHT OUTER JOIN 모두를 하는 것이다.
- Oracle db에서는 OUTER JOIN 을 할 때 "(+)" 기호를 사용해서 할 수 있다.
LEFT OUTER JOIN 과 RIGHT OUTER JOIN
- LEFT OUTER JOIN 은 두개의 테이블에서 같은 것을 조회하고 왼쪽 테이블에만 있는 것을 포함해서 조회된다.
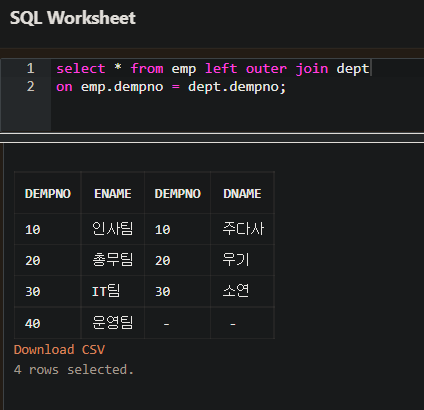
위의 예처럼 40번까지 조회된다.
- RIGHT OUTER JOIN 은 두 개의 테이블에서 같은 것을 조회하고 오른쪽 테이블에만 있는 것을 포함해서 조회된다.
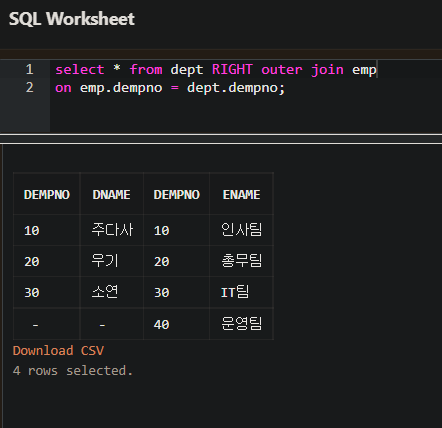
- 위의 예처럼 오른쪽에 있는 EMP 테이블의 번호인 40번까지 모두 조회된다.
- 즉 DEPT 테이블의 NULL 인 행도 조회된다.
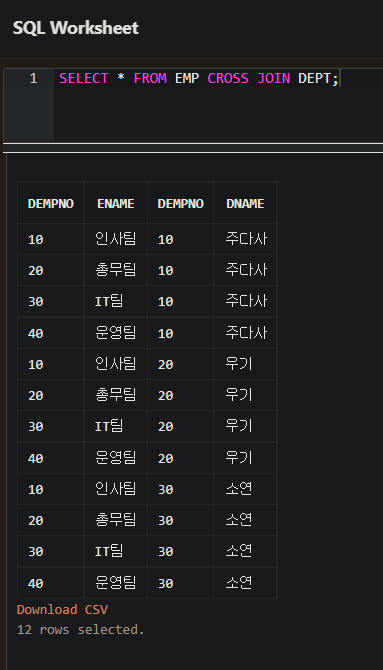
- CROSS JOIN
- CROSS JOIN 은 조인 조건구 없이 2개의 테이블을 하나로 조인한다.
- 조인구가 없기 때문에 카테시안 곱이 발생한다.
- 예를 들어 행이 14개 있는 테이블과 행이 4개 있는 테이블을 조인하면 56개의 행이 조회된다.
- CROSS JOIN 은 FROM 절에 "CROSS JOIN" 구를 사용하면 된다.
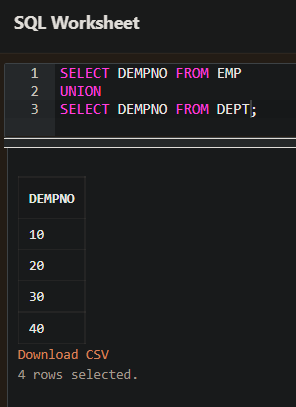
- UNOIN 을 사용한 합집합 구현
UNOIN
- UNOIN 연산은 두 개의 테이블을 하나로 만드는 연산이다.
- 즉, 2개의 테이블을 하나로 합치는 것이다. 주의사항은 두 개의 테이블의 칼럼 수, 칼럼의 데이터 형식 모두가 일치해야 한다. 만약 두 개의 테이블에 UNION 연산이 사용될 때 칼럼 수 혹은 데이터 형식이 다르면 오류가 발생한다.
- UNION 연산은 두 개의 테이블을 하나로 합치면서 중복된 데이터를 제거한다.
- 그래서 UNOIN 은 정렬 과정을 발생시킨다.
UNOIN ALL
- UNION ALL 은 두 개의 테이블을 하나로 합치는 것이다. UNION처럼 중복을 제거하거나 정렬을 유발하지 않는다.
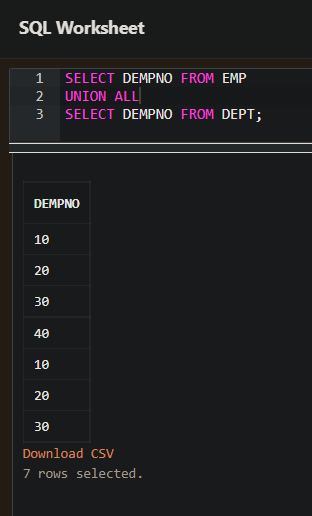
단순하게 테이블을 합치는 것
- 차집합을 만드는 MINUS
- MINUS 연산은 두 개의 테이블에서 차집합을 조회한다. 즉, 먼저 쓴 SELECT문에는 있고 뒤에 쓰는 SELECT 문에는 없는 집합을 조회하는 것이다.
- MS-SQL 에서는 MINUS와 동일한 연산이 EXCEPT 이다.
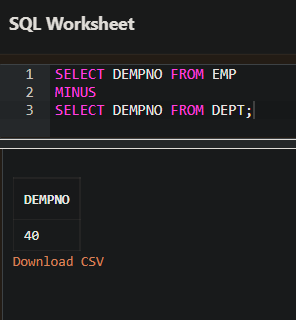
앞의 SELECT 문에서 뒤의 SELECT 문의 조회 결과를 빼면 EMP 테이블에만 있는 DEMPNO 인 40 만 조회된다.
POINT2 계층형 조회 (Connect by)
- 계층형 조회는 Oracle db에서 지원하는 것으로 계층형으로 데이터를 조회할 수 있다.
- 예를들어 부장에서 차장, 차장에서 과장, 과장에서 대리, 대리에서 사원 순으로 트리형태의 구조를 위에서 아래로 탐색하면서 조회하는 것이다. 물론 역방향 조회도 가능하다.
계층형 조회 테스트 데이터 입력
create table emp (
empno number(10) primary key,
ename varchar2(20),
deptno number(10),
mgr number(10),
job varchar2(20),
sal number(10) );
insert into emp values(1000, 'test1', 20, null, 'clerk', 800);
insert into emp values(1001, 'test2', 30, 1000, 'salesman', 1800);
insert into emp values(1002, 'test3', 30, 1000, 'salesman', 1275);
insert into emp values(1003, 'test4', 20, 1000, 'manager', 2975);
insert into emp values(1004, 'test5', 30, 1000, 'salesman', 1250);
insert into emp values(1005, 'test6', 30, 1001, 'manager', 2850);
insert into emp values(1006, 'test7', 10, 1001, 'manager', 2450);
insert into emp values(1007, 'test8', 20, 1006, 'analyst', 3000);
insert into emp values(1008, 'test9', 30, 1006, 'president', 5000);
insert into emp values(1009, 'test10', 30, 1002, 'salesman', 1500);
insert into emp values(1010, 'test11', 20, 1002, 'clerk', 1100);
insert into emp values(1011, 'test12', 30, 1001, 'clerk', 950);
insert into emp values(1012, 'test13', 20, 1000, 'analyst', 3000);
insert into emp values(1013, 'test14', 10, 1000, 'clerk', 1300);
- Connect by 는 트리 형태의 구조로 질의를 수행하는 것으로 START WITH 구는 시작 조건을 의미하고 CONNECT BY PRIOR 는 조인 조건이다. Root 노드로부터 하위 노드의 질의를 실행한다.
- 게층형 조회에서 MAX(LEVEL)을 사용하여 최대 계층 수를 구할 수 있다. 즉, 계층형 구조에서 마지막 Leaf Node 의 계층값을 구한다.
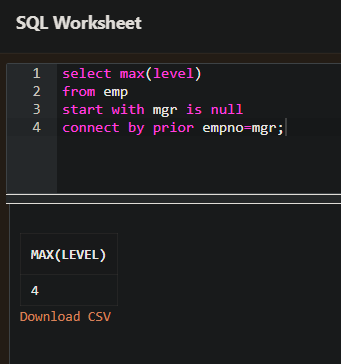
위의 sql 에서 MAX(LEVEL) 이 4 이므로 트리의 최대 깊이는 4 이다.
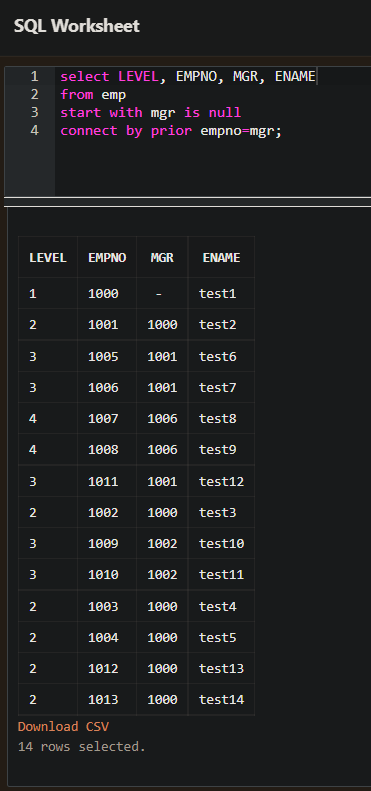
- 위의 예에서 empno와 mgr 칼럼 모두 사원 번호가 입력되어 있다.
- 하지만 mgr은 관리자 사원번호를 가지고 있다. 즉, mgr 1000번은 1001과 1002의 사원을 관리한다.
- 계층형 조회 결과를 명확히 보기 위해서 LPAD 함수를 사용할 수 있다.
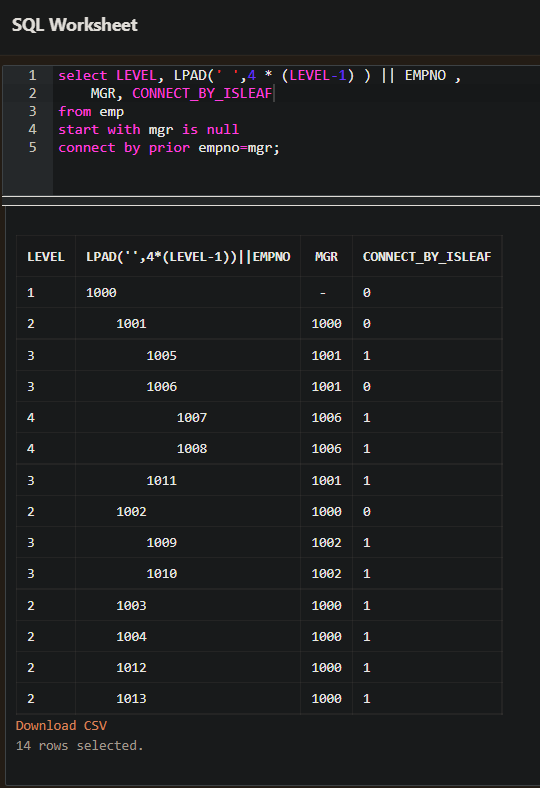
- 위의 예를 보면 4*LEVEL-1 이 있다. LEVEL값이 ROOT 이면 1이 된다. 따라서 4*(1-1)=0 이 된다.
- 즉, ROOT 일 때는 LPAD(' ', 0) 이므로 아무런 의미가 없다.
- 하지만 LEVEL 값이 2가 되면 4*(2-1)=4 가 된다. LPAD(' ', 4) 이므로 왼쪽 공백 4칸을 화면에 찍게 된다.
- 결과적으로 LPAD는 트리 형태로 보기 위해서 사용한 것이다. 왜냐하면 LEVEL 값은 ROOT에 1을 되돌리고 그 다음 자식은 2, 그 다음 자식은 3이 나오기 때문이다.
CONNECT BY 키워드
| 키워드 | 설명 |
| LEVEL | 검색 항목의 깊이를 의미한다. 즉, 계층구조에서 가장 상위 레벨이 1이된다. |
| CONNECT_BY_ROOT | 게층 구조에서 가장 최상위 값을 표시한다. |
| CONNECT_BY_ISLEAF | 계층 구조에서 가장 최하위를 표시한다. |
| SYS_CONNECT_BY_PATH | 게층구조의 전체 전개 경로를 표시한다. |
| NOCYCLE | 순환구조가 발생지점까지만 전개된다. |
| CONNECT_BY_ISCYCLE | 순환구조 발생 지점을 표시한다. |
POINT3. 서브쿼리 (Subquery)
- Main query와 Subquery
- subquery는 SELECT문 내에 다시 SELECT문을 사용하는 SQL 문이다.
- Subquery의 형태는 FROM구에 SELECT문을 사용하는 인라인 뷰(Inline View)와 SELECT문에 Subquery를 사용하는 스칼라 서브쿼리(Scala Subquery)등이 있다.
- WHERE 구에 SELECT 문을 사용하면 서브쿼리라고 한다.
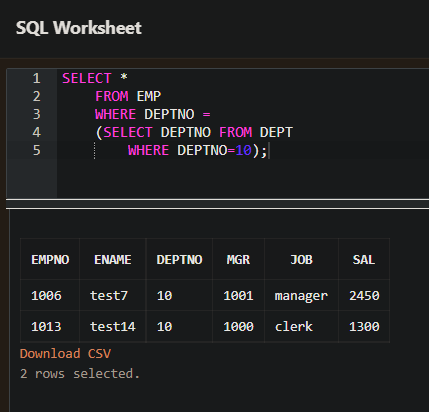
- 위의 예에서 WHERE 구에 있는 SELECT 문은 서브쿼리 이고 괄호 내에 SELECT 문을 사용한다.
- 서브쿼리 밖에 있는 SELECT 문은 메인쿼리이다.
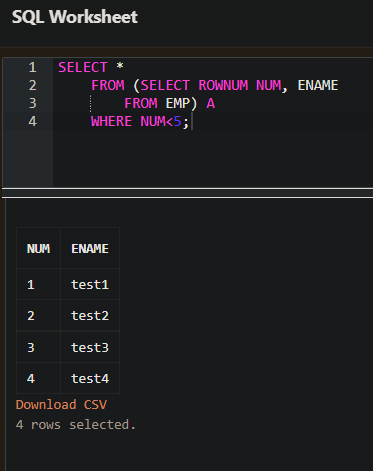
- FROM 구에 SELECT 문을 사용하여 가상의 테이블을 만드는 효과를 얻을 수 있다.
- 이렇게 FROM구에 SELECT 문을 사용한 것이 인라인 뷰(Inline View)이다.
- 단일 행 서브쿼리와 다중 행 서브쿼리
- 서브쿼리(Subquery) 는 반환하는 행 수가 한 개인 것과 여러 개인 것에 따라서 단일 행 서브쿼리와 멀티 행 서브쿼리로 분류된다.
- 단일 행 서브쿼리는 단 하나의 행만 반환하는 서브쿼리로 비교연산자를 사용한다.
- 다중 행 서브쿼리는 여러 개의 행을 반환하는 것으로 IN, ANY, ALL, EXISTS를 사용해야 한다.
서브쿼리 종류(반환 행)
| 서브쿼리 종류 | 설명 |
| 단일 행 서브쿼리 | - 서브쿼리를 실행하면 그 결과는 반드시 한 행만 조회된다. - 비교 연산자인 =, <, >, <=, >=, <> 를 사용한다 |
| 다중 행 서브쿼리 | - 서브쿼리를 실행하면 그 결과는 여러 개의 행이 조회된다. - 다중 행 비교 연산자인 IN, ANY, ALL, EXISTS를 사용한다. |
- 다중 행 서브쿼리
- 다중 행 서브쿼리는 서브쿼리 결과가 여러 개의 행을 반환하는 것으로 다중 행 연산자를 사용해야 한다.
다중 행 비교 연산자
| 다중 행 연산 | 설명 |
| IN | Main query의 비교 조건이 Subquery의 결과 중 하나만 동일하면 참이 된다. (or조건) |
| ALL | - Main query와 Subquery의 결과가 모두 동일하면 참이된다 - < ALL : 최솟값을 반환한다. - > ALL : 최댓값을 반환한다. |
| ANY | - Main query의 비교조건이 Subquery의 결과 중 하나 이상 동일하면 참이 된다. - < ANY : 하나라도 크게 되면 참이 된다. - > ANY : 하나라도 작게 되면 참이 된다. |
| EXISTS | Main query와 Subquery의 결과가 하나라도 존재하면 참이 된다. |
- IN
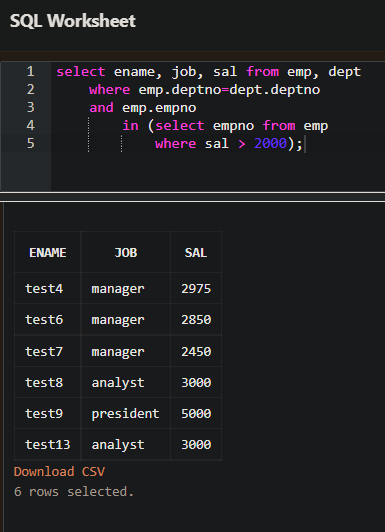
- 급여가 2000보다 큰 사원번호를 조회한 후에 emp.empno를 조회한다.
- 위의 예에서 emp테이블에서 sal 이 2000원 초과인 사원번호를 반환하고 반환된 사원번호와 메인쿼리에 있는 사원번호와 비교해서 같은 것을 조회하는 것이다.
- ALL
메인쿼리와 서브쿼리의 결과가 모두 동일하면 참이 된다.
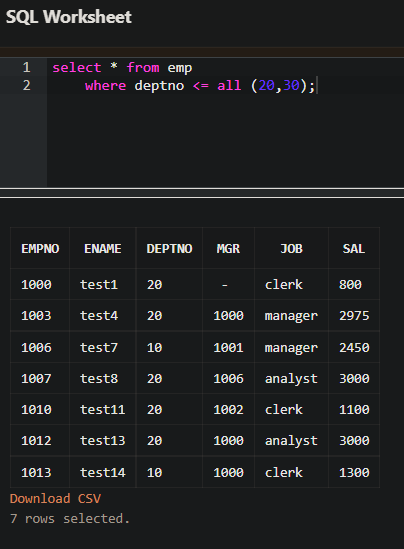
- 위의 예는 DEPTNO 가 20, 30 보다 작거나 같으면 조회하는 것이다.
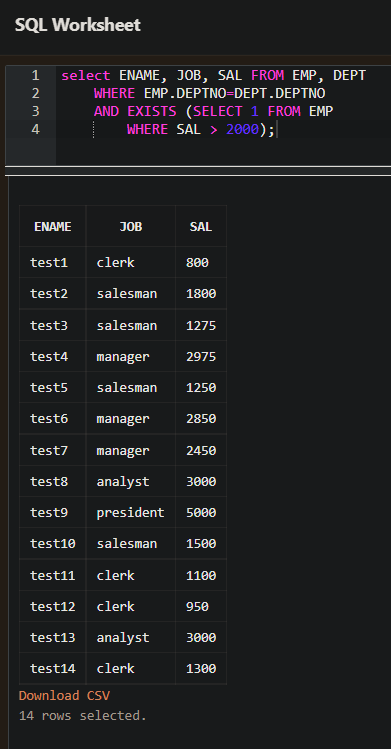
- EXISTS
- EXISTS는 Subquery로 어떤 데이터 존재 여부를 확인하는 것이다.
- 즉, EXISTS의 결과는 참과 거짓이 반환된다.
- 다음의 예는 직원 중에서 급여가 2000이상이 있으면 참이 반환되고 없으면 거짓이 반환된다.
- 스칼라(Scala) Subquery
- 스칼라 서브쿼리는 반드시 한 행과 한 칼럼만 반환하는 서브쿼리이다.
- 만약 여러 행이 반환되면 오류가 발생한다.
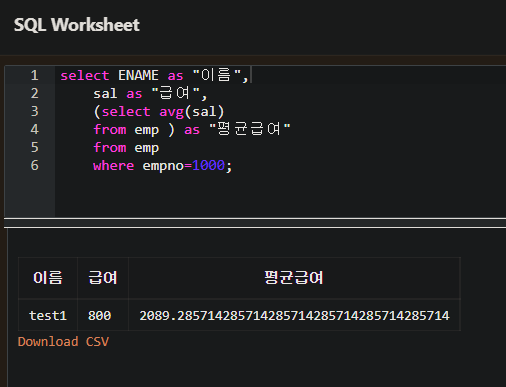
한개의 행만 조회 되어야 한다.
- 앞의 예처럼 급여를 조회할 때 평균 급여를 같이 계산하여 조회한다.
- 스칼라 서브쿼리를 사용해서 직원의 평균 급여를 계산한 것이다.
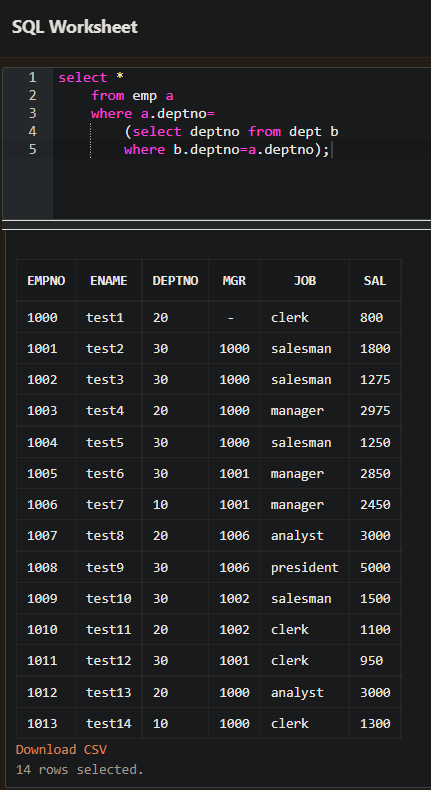
- 연관(Correlated) Subquery
- 연관 Subquery 는 서브커리 내에서 메인쿼리 내의 칼럼을 사용하는 것을 의미한다.
오늘은 여기까지
지금 시간 5.23 08:51
조금 자고 이따가 오후에 일어나서
진도를 끝내보자
'파이썬 > SQLD' 카테고리의 다른 글
| [SQLD] 시험준비 4주 2일차 1 - SQL 활용 확인문제 (0) | 2022.05.24 |
|---|---|
| [SQLD] 시험준비 4주 1일차 - SQL 활용2 (0) | 2022.05.23 |
| [SQLD] 시험준비 3주 4일차 - SQL 기본 문제풀이 (0) | 2022.05.20 |
| [SQLD] 시험준비 3주 3일차 - DML4, DCL, TCL (0) | 2022.05.19 |
| [SQLD] 시험준비 3주 2일차 - DML3 (0) | 2022.05.18 |