#AWS Certified Solutions Architect Associate
AWS-DVA 과정에서 나오지 않았거나, 기억이 안나는 부분 메모
Athena
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/what-is.html
Amazon Athena란 무엇인가요? - Amazon Athena
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
비용을 줄이는 방법
성능 향상 - columnar date, compress data, partition dataset연합 쿼리 - lambda data source connectors
Redshift

snapshot & DR
https://docs.aws.amazon.com/ko_kr/redshift/latest/mgmt/working-with-snapshots.html
Amazon Redshift 스냅샷 및 백업 - Amazon Redshift
다음 예는 restore-table-from-cluster-snapshot AWS CLI 명령을 사용하여 my-snapshot-id의 sample-database 스키마에서 my-source-table 테이블을 복원합니다. AWS CLI 명령 describe-table-restore-status를 사용하여 복원 작업의
docs.aws.amazon.com

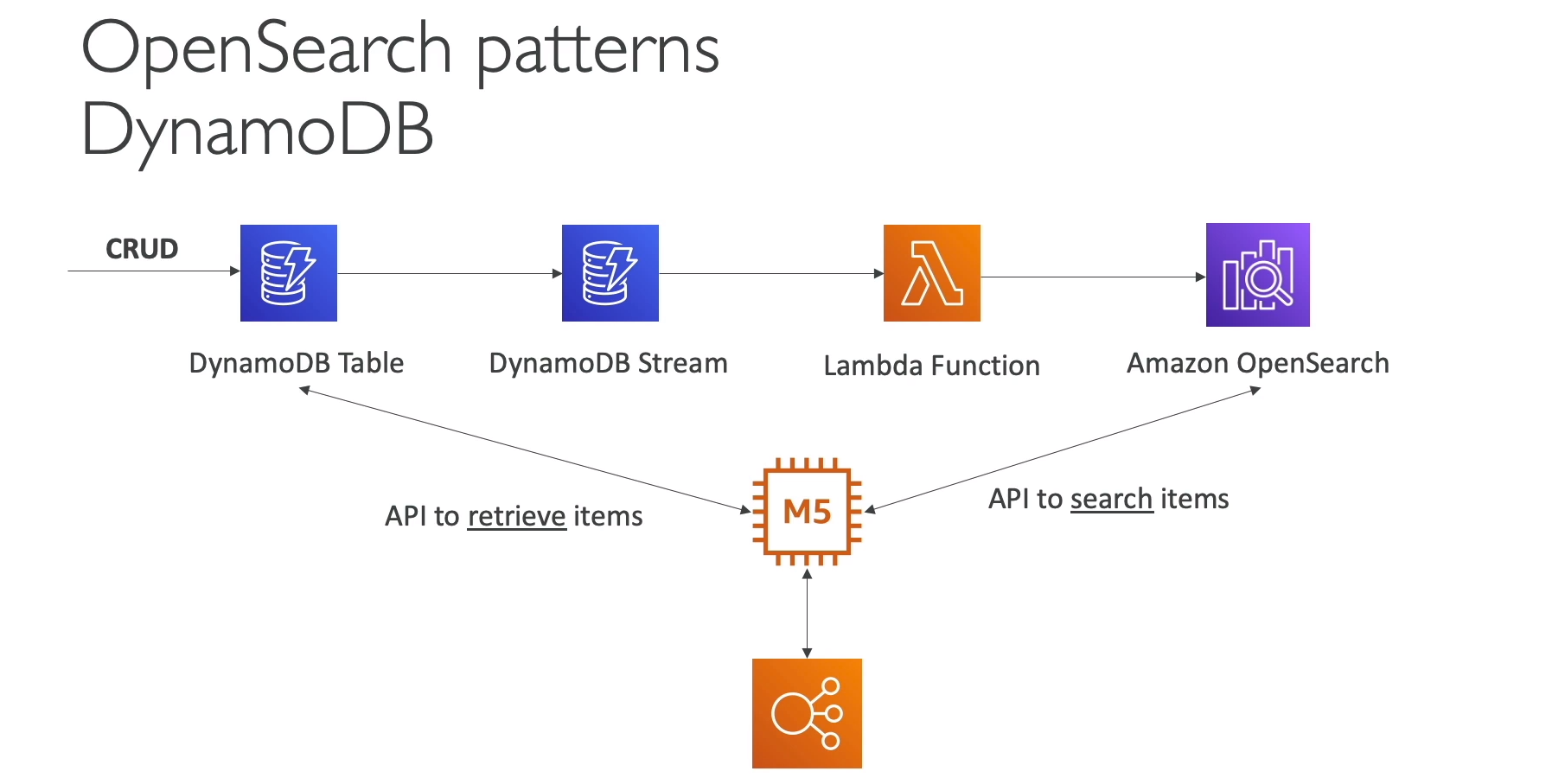
Opensearch Service
- 비용 절감
- 배포 유연성
- 검색 혁신
- 비용 효율적인 저장 공간 옵션
- 여러 위치에서 통합된 검색 환경
- 인덱스를 기반으로 데이터를 저장
- 각 인덱스는 샤드로 구성되어 있음
- 각 샤드는 루씬의 인덱스


Amazon EMR
Elastic MapReduce
빅데이터 하둡 클러스터
Amazon Quiksight


Amazon QuickSight는 클라우드 기반의 비즈니스 인텔리전스(BI) 서비스로, 사용자가 대시보드를 통해 데이터를 시각화하고 분석하며 보고하는 데 도움이 됩니다1. QuickSight는 기본적으로 머신러닝 기능과 통합되어 있어, 사용량을 기준으로 한 요금으로 모든 사용자에게 인사이트를 제공합니다1.
QuickSight의 사용자 및 그룹 관리는 AWS Identity and Access Management (IAM)과는 약간 다릅니다. IAM은 AWS 클라우드 인프라 내에서 신분과 접속/접근을 관리하기 위한 서비스로, 사용자(Users), 그룹(Groups), 역할(Roles), 정책(Policies)으로 구성되어 있습니다2.
QuickSight와 IAM의 주요 차이점은 다음과 같습니다:
- 적용 대상: IAM은 사용자를 대상으로 하지만, QuickSight는 AWS 계정을 대상으로 합니다34.
- 권한 부여: IAM에서는 정책을 통해 권한을 부여하지만, QuickSight에서는 이메일 초대를 통해 사용자에게 액세스 권한을 부여합니다3.
- 사용자 데이터: QuickSight는 IAM 또는 IAM Identity Center에 구성된 사용자 액세스와 독립적인 사용자 저장소를 유지 관리합니다3.
- 역할(Role): IAM의 역할은 권한(Policy)을 갖는다는 점에서 IAM 사용자와 비슷하지만, IAM 사용자는 딱 그 사용자에게만 권한이 적용되지만, IAM 역할은 그 권한이 필요한 사용자라면 얼마든지 획득할 수 있습니다5.
이러한 차이점들로 인해, QuickSight와 IAM은 각각의 상황에 따라 적절하게 사용될 수 있습니다. QuickSight는 데이터 시각화와 분석에 초점을 맞추고 있으며, IAM은 AWS 리소스에 대한 보안 및 액세스 제어에 중점을 두고 있습니다. 이 두 가지 서비스를 적절하게 활용하면, AWS 환경에서의 데이터 관리와 보안을 효과적으로 수행할 수 있습니다.
Glue
데이터 분석을 위한 데이터 변환 도구로서 유용

AWS Lake Formation
AWS Lake Formation은 데이터 레이크 구축을 위한 완전 관리형 서비스입니다1. 이 서비스는 분석 및 기계 학습을 위한 데이터를 중앙에서 관리하고 보호하며 전 세계적으로 공유할 수 있도록 지원합니다2.
Lake Formation의 주요 기능은 다음과 같습니다:
- 데이터 이동, 저장, 카탈로그 관리: Amazon S3의 데이터 레이크 데이터와 해당 메타데이터에 대한 세분화된 액세스 제어를 관리할 수 있습니다2.
- 보안 정책 적용: 여러 AWS 서비스에 걸쳐 보안 정책을 적용할 수 있습니다1.
- 데이터 인사이트 수집 및 관리: 데이터 인사이트의 수집 및 관리가 가능합니다1.
Lake Formation은 데이터 레이크의 데이터에 대한 액세스 제어를 관리할 수 있는 단일 장소를 제공하며, 데이터베이스, 테이블, 열, 행 및 셀 수준에서 데이터에 대한 액세스를 제한하는 보안 정책을 정의할 수 있습니다2. 이러한 정책은 외부 ID 공급자를 통해 페더레이션할 때 IAM 사용자 및 역할, 사용자 및 그룹에 적용됩니다2.


Kinesis Data Analytics
Kinesis Data Analytics는 실시간 스트리밍 데이터를 분석하는 AWS 서비스입니다. 이 서비스는 두 가지 주요 활용 방법이 있습니다: SQL 애플리케이션과 Apache Flink.
- SQL 애플리케이션: SQL 애플리케이션을 위한 Kinesis Data Analytics를 사용하면 표준 SQL을 사용하여 스트리밍 데이터를 처리하고 분석할 수 있습니다1. 이 서비스를 사용하면 스트리밍 소스에 대해 강력한 SQL 코드를 작성하고 실행하여 시계열 분석을 수행하고, 실시간 대시보드를 제공하고, 실시간 지표를 생성할 수 있습니다1. Kinesis Data Analytics에서 결과를 전송할 대상을 구성할 수도 있습니다1.
- Apache Flink: Apache Flink는 오픈 소스 스트리밍 처리 프레임워크로, Kinesis Data Analytics에서도 지원합니다23. Flink를 사용하면 실시간 스트리밍 애플리케이션을 빠르게 구축하고 실행할 수 있습니다2. Flink 애플리케이션은 강력하고 인기 있지만, 병렬 컴퓨팅이나 컨테이너 리소스의 확장과 조정이 필요하기 때문에 관리하기가 쉽지 않습니다3. Amazon Managed Service for Apache Flink를 사용하면 최소한의 코딩으로 데이터 소스 또는 대상을 설정 및 통합하고, Amazon Kinesis Data Streams 와 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 를 비롯한 수많은 데이터 소스에서 1초 미만의 지연 시간으로 데이터를 지속적으로 처리하고, 이벤트에 실시간으로 대응할 수 있습니다3.

Amazone Managed Service for Apache Flink
https://aws.amazon.com/ko/managed-service-apache-flink/
스트림 처리 - Amazon Managed Service for Apache Flink - AWS
최소한의 코드만으로 데이터 소스와 대상을 설정 및 통합하고, 1초 미만의 지연 시간으로 데이터를 지속적으로 처리하며 이벤트에 실시간으로 대응합니다.
aws.amazon.com
Amazon MSK
**Amazon Managed Streaming for Apache Kafka (Amazon MSK)**는 Apache Kafka를 사용하여 스트리밍 데이터를 처리하는 애플리케이션의 구축 및 실행을 위해 사용할 수 있는 완전관리형 서비스입니다1.
Amazon MSK의 주요 기능은 다음과 같습니다:
- 클러스터 관리: Amazon MSK는 클러스터 생성, 업데이트, 삭제와 같은 컨트롤 플레인 작업을 제공합니다1.
- 데이터 보존: Amazon MSK는 주제 수준에서 보존 기간을 관리할 수 있습니다2.
- 암호화: Amazon MSK는 AWS Key Management Service (AWS KMS)와 통합되어 투명한 서버 측 암호화를 제공합니다2.
Amazon MSK는 클러스터에 대한 가장 일반적인 장애 시나리오를 감지하고 자동으로 복구하므로 생산자 및 소비자 애플리케이션이 최소한으로 영향을 받으면서 쓰기 및 읽기 작업을 계속할 수 있습니다1. 복구 후 생산자와 소비자 앱은 결함 이전에 사용한 것과 동일한 브로커 IP 주소와 계속 통신할 수 있습니다1.

Big Data Ingestion Pipeline

'AWS > AWS Certified SAA' 카테고리의 다른 글
| [Udemy][AWS-SAA][Section-23] Machine Learning (0) | 2023.12.13 |
|---|---|
| AWS-SAA Examtopic 번역 오답노트 31~60 (0) | 2023.12.12 |
| AWS-SAA Examtopic 번역 오답노트 1~30 (0) | 2023.12.11 |
| [Udemy][AWS-SAA][Section-21] Databases in AWS (0) | 2023.12.08 |
| [Udemy][AWS-SAA][Section-20] Serverless Solution Architecture Discussion (0) | 2023.12.06 |