#AWS Certified Developer Associate
379. 단계 함수 개요
AWS Step Functions
단계 함수는 워크플로우를 상태 머신으로 모델링 하게 해줌
- 워크플로우당 하나의 상태 머신(state machines) 을 가질 수 있음
- 주문 이행, 데이터 처리, 웹 애플리케이션이나 원하는 어떤 워크플로우에서 사용 가능
기본적으로 워크플로우는 JSON 으로 정의함
- 이 json 은 워크플로우를 시각화 함
- 워크플로우 수행의 이력(history) 도 확인할 수 있음
워크플로우 시작 전에 SDK API 호출을 사용할 수 있음
API Gateway , Clouidwatch Event, EventBridge 사용 가능
콘솔에서 수동으로 Step Functions 을 실행할 수 있음

위 시각 자료에서 여러 박스가 있는데 이 박스를 태스크 라고 함
Task States
태스크 상태는 상태 머신에 어떤 작업을 할 때 사용됨

앱 서버가 step function 에 의해 호출되는 것이 아니라 앱 서버에 있는 step functions 이 step functions 을 가져와서 활동을 찾고 작업을 수행한다는 측면에서 더 자유롭다고 함
AWS 의 SWF 라는 서비스가 동작하는 방식과 유사
예시 ) 람다 함수 호출을 위해 태스크 상태 정의
json 사용

step function - states
choice state - 브랜치 또는 기본 브랜치로 보낼 조건을 테스트함
fail or succeed state - 워크플로우의 성공 또는 실패, step functions 의 실행을 중지함
pass state - 입력값을 출력값이 전달하거나 작업을 수행하지 않고 고정된 데이터를 주입함
wait state - 특정 시간 동안 지연하거나 특정 날짜나 시간까지 지연시킴
map state - 단계들을 동적으로 반복함
parallel state - 브랜치의 수행을 병렬적으로 수행함

380. 단계 함수 - 실습

단계 함수 콘솔로 가서 시작을 누르면 hello world 예제를 확인할 수 있다
json 문서를 기반으로 오른쪽 워크 플로우가 시작된다고 한다
다음
이름은 그대로 해주고 새 역할 생성도 허용해주고 상태 머신 생성

이 워크 플로우를 실행하기 위해 "IsHelloWorldExample" 이 true 인지 false 인지 입력해달라고 한다
여기서 true 라고 하고 실행 시작을 누르면

상태머신 세부정보를 확인할 수 있다

시각 자료로 워크플로우 차트를 볼 수 있다

이벤트로 어떻게 워크플로우가 진행되었는지 확인할 수 있다
start 에서 패스되어 hello world example 로 가서 값을 확인하고
3초간 대기한 후
병렬 상태를 실행해서
hello 와 world 를 결과값으로 리턴한다
이벤트를 각각 눌러보면 디버깅된 내용을 볼 수 있어 유용하다고 함
새 실행을 눌러 이번엔 값을 false 로 하고 실행해보면


IsHelloWorldExample 에서 false 로 값을 넣었기때문에 실패함

실행 이벤트 이력 탭에서 직접 디버깅 할 수 있다
이제 커스텀 상태 머신을 만들어본다고 한다

코드로 워크 플로 작성을 선택하고 표준을 선택
아래 정의에서 데이터 전달 항목을 지정해줘야 하는데
이를 위해 람다 함수를 하나 만든다고 함
함수 이름은 HelloFunction 이라고 해주고 런타임은 nodejs.14 으로 놓고 함수 생성
함수에 사용할 코드는 아래 예제를 사용
exports.handler = (event, context, callback) => {
callback(null, "Hello, " + event.who + "!");
};테스트 json 을 "who" : "string" 으로 넣고 테스트 해보

hello yuni 를 반환한다
다시 상태 머신 생성 화면으로 가서
정의에 있는 json 코드를 아래 예제 코드로 대체한다
{
"Comment": "A Hello World example of the Amazon States Language using Pass states",
"StartAt": "Invoke Lambda function",
"States": {
"Invoke Lambda function": {
"Type": "Task",
"Resource": "<LAMBDA FUNCTION ARN>",
"InputPath": "$",
"Next": "Choice State"
},
"Choice State": {
"Type": "Choice",
"Choices": [
{
"Variable": "$",
"StringMatches": "*Stephane*",
"Next": "Is Teacher"
}
],
"Default": "Not Teacher"
},
"Is Teacher": {
"Type": "Pass",
"Result": "Woohoo!",
"End": true
},
"Not Teacher": {
"Type": "Fail",
"Error": "ErrorCode",
"Cause": "Stephane the teacher wasn't found in the output of the Lambda Function"
}
}
}
코드를 붙여넣고 오른쪽 플로우 차트의 새로고침을 눌러보면

이렇게 json 문서에 대한 시각 자료가 플로우 차트로 나타난다
빨갛게 오류가 난 부분은 람다 arn 을 가져와서 붙여넣어준다
오류가 난 resource 아래의 inputpath 는 람다 함수에 전달되는 값이라고 함
워크 플로우의 입력값은 기본적으로 함수로 전달될 것이라고 함 - 첫번째 태스크이기 때문
states 로 정의된 invoke lambda funciton - choice state - is teacher , not teacher 에서 각각 유형을 정의할 수 있고 결과를 반환하거나 다음 스텝을 정의할 수 있다
다음
상태 머신 이름을 MyStateMachineDemo 로 해주고 새 영할 생성을 허용해 준 후 생성

잘 생성이 됬다
아래의 실행 시작에
"who" : "string" 을 입력해줘서 실행해보면
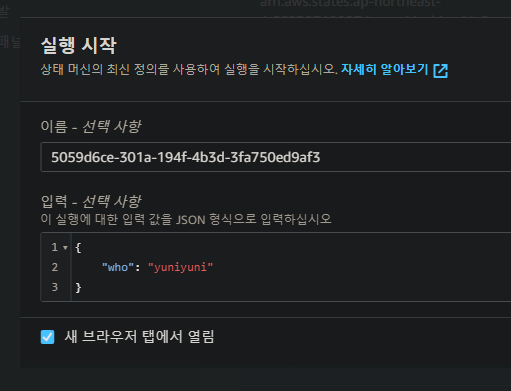

입력값도 확인할 수 있다
잘 실행된 모습
매치되지 않는 다른 입력값을 입력하면 위의 helloworld 예제와 같이 실패할것이다
381. 단계 함수 - 오류 처리
Error Handling in Step Functions
모든 오류 처리는 Step Functions 에 의해 태스크의 외부에서 일어나야 함
오류 상황 :
- 상태 머신 정의에 문제가 있을 때
- 람다 함수가 예외처리하여 태스크가 실패할 때
- 네트워크 파티션 이벤트와 같은 일시적인 실패
단계 함수 오류 처리를 위한 두가지 방법
- Retry (to retry failed state)
- Catch (transition to failure path)
애플리케이션 코드가 아닌 단계 함수에서 위 처리를 정의해야 함
- 애플리케이션이 단순해지고 step function 에 좋은 매커니즘이 있다면 재시도의 실행 기록뿐만 아니라 step function 이력에서 직접 캐치할 수 있기 때문
사전 정의된 오류 코드 :
States.ALL - 어떤 오류 이름과도 매칭
States.Timeout - 태스크가 시간초과로 설정된 시간보다 길게 실행 하거나 활동으로부터 아무 신호도 받지 못했을 때
States.TaskFailed - 태스크의 실행이 자체적으로 실패할 때 (ex. 람다 함수 예외처리 등)
States.Permissions - 어떤 코드를 실행할 권한이 충분하지 않을 때
상태(state) 자체에서도 오류를 보고할 수 있음
- 이를 step functions 에서 캐치할 수 있음
Retry (Task or Parallel State)
재시도는 오류를 기반으로 재시도할 작업 및 횟수를 정의할 수 있음
위에서 아래로 평가됨

ErrorEquals - 특정 오류를 매치함
IntervalSeconds - 재시도 전에 얼마나 오래 대기해야 하는지 설정
BackoffRate - 재시도 후의 지연을 곱함 - 기하 급수적인 백오프를 구현하기 위함
MaxAttempts - 재시도의 횟수, 기본값은 3이고 0일경우 재시도를 하지 않음
모든 시도를 마치면 Catch 블록이 실행됨
Catch (Task or Parallel State)
캐치도 비슷한 논리를 가짐

Next - 상태를 다음 으로 보냄
ResultPath - 다음 필드로 지정된 상태, 전송되는 입력값의 경로를 결정함
ResultPath
예제 task
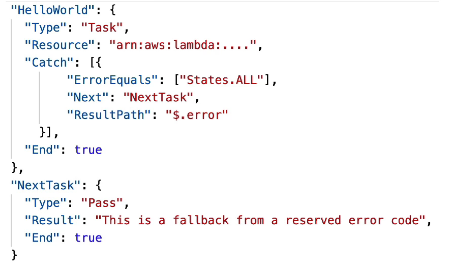
위 태스크에는 1개의 캐치가 있음
캐치는 states.all 로 모든 오류를 캐치함
nexttask 로 가라고 하고
resultpath 는 "$.error" 이다

$.error 는 입력값에 오류를 포함할 수 있게 해줌
결과값은 입력값을 그대로 가져오지만 오류메세지와 오류 관련 정보를 포함하는 오류 블록이 포함됨
ResultPath 는 입력값으로부터의 오류를 다음 태스크의 결괏값으로 어떻게 전달할 것인지를 나타냄
382. 단계 함수 - 오류 처리 실습
먼저 오류를 전달할 람다 함수를 만든다고 함

테스트를 해보면 아래와 같이 에러 메세지를 반환하는 간단한 함수다

새로운 상태 머신을 만든다고 함
코드로 워크플로 작성을 선택하고 아래 코드를 정의에 붙여넣어줌
{
"Comment": "A Retry and Catch example of the Amazon States Language using an AWS Lambda Function",
"StartAt": "InvokeMyFunction",
"States": {
"InvokeMyFunction": {
"Type": "Task",
"Resource": "<enter resource ARN here>",
"Retry": [
{
"ErrorEquals": [
"CustomError"
],
"IntervalSeconds": 1,
"MaxAttempts": 2,
"BackoffRate": 2
},
{
"ErrorEquals": [
"States.TaskFailed"
],
"IntervalSeconds": 30,
"MaxAttempts": 2,
"BackoffRate": 2
},
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 5,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"CustomError"
],
"Next": "CustomErrorFallback"
},
{
"ErrorEquals": [
"States.TaskFailed"
],
"Next": "ReservedTypeFallback"
},
{
"ErrorEquals": [
"States.ALL"
],
"Next": "CatchAllFallback"
}
],
"End": true
},
"CustomErrorFallback": {
"Type": "Pass",
"Result": "This is a fallback from a custom lambda function exception",
"End": true
},
"ReservedTypeFallback": {
"Type": "Pass",
"Result": "This is a fallback from a reserved error code",
"End": true
},
"CatchAllFallback": {
"Type": "Pass",
"Result": "This is a fallback from a reserved error code",
"End": true
}
}
}

오류를 각각 어떻게 처리할지 정의해놓은 코드이다
람다 arn 을 붙여넣어주고
다음
상태머신 이름을 MyStateMachineError 로 해주고 새 역할 생성 허용 한 후 상태머신 생성
실행 시작을 새 탭으로 열어서 확인해보면


설정한 재시도 횟수 시도 이후 다음 단계로 넘어가서 단계 함수가 마무리 된 모습
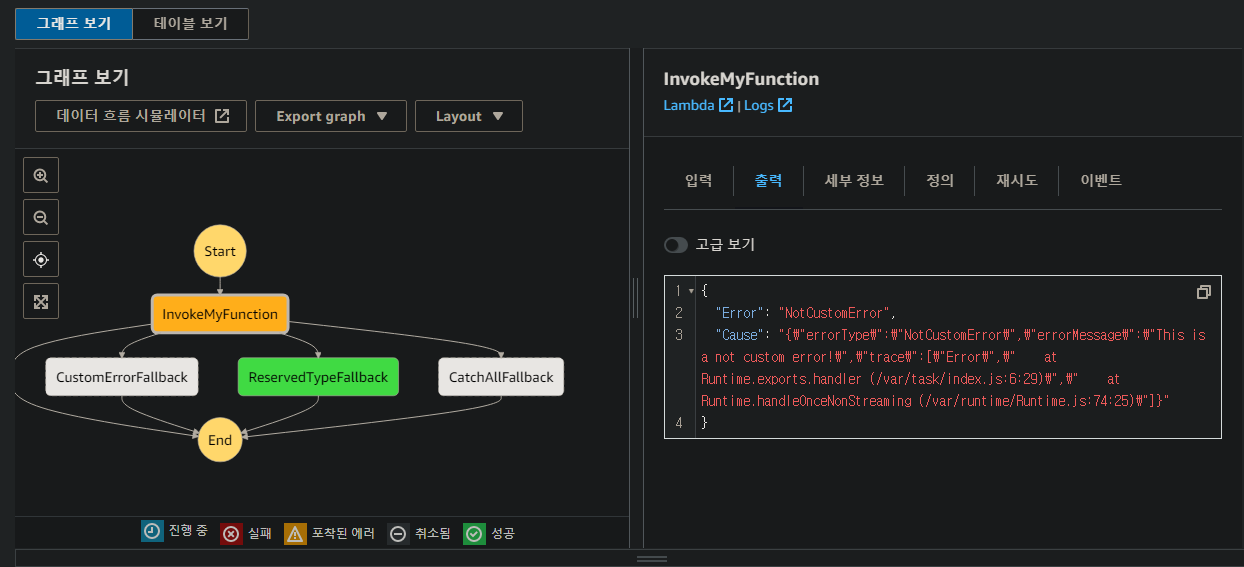
람다 함수로 다시 이동해서 에러 값을 변경해주면 다른 에러 핸들링을 테스트하는 것도 가능하다
위와 같이 단계 함수에서는 오류의 유형을 기반으로 다른 재시도 논리와 다른 캐치 논리를 가짐
383. 단계 함수 - Standard vs Express
Standard Workflows :
최대 기간 1년
초당 2,000개의 표준 워크플로우를 시작할 수 있음
계정당 1초에 4,000 상태 전환을 가질 수 있음
가격은 상태 전환 별로 책정됨 (상태전환 - 한번에 실행을 한단계 할때)
실행 이력을 볼 수 있음
워크플로우가 정확히 한번 실행됨
Express Workflows:
최대 기간 5분 - 빨리 완료 되는 작업에 적합함
초당 100,000 개의 익스프레스 워크플로우를 시작할 수 있음
가질 수 있는 상태 전환은 거의 무제한임
실행한 실행 숫자와 기간, 소비한 메모리에 따라 가격이 책정됨 - 람다 함수와 아주 비슷함
실행 자체에 이력은 없음 - cloudwatch logs 를 이용해 조사할 수 있음
적어도 한번의 워크플로우가 실행됨
익스프레스의 경우 고처리량의 빠른 워크플로우를 위한 유형
표준의 경우 더 길고 느린 처리량을 위한 유형
실습이 끝난 후 상태머신은 모두 삭제해줬음
(03.05 끝)
(3.7 시작)
384. AppSync 개요
GraphQL
- 애플리케이션이 필요한 데이터를 쉽게 얻을 수 있음
- 새로운 스타일의 api
- 기본적으로 원하는 필드를 요청하면 GraphQL 이 이를 반환함
- 하나 이상 소스의 데이터를 그래프로 결합할 수 있음
- graphQL 의 데이터셋은 NoSQL 데이터 스토어, 관계형 데이터베이스, HTTP APIs 등 모두를 결합함
- AppSync 의 GraphQL 은 DynamoDB, Aurora, Elasticsearch 등 다른 소스와 통합됨
- AWS Lambda 로 패턴을 확장할 수 있음
실시간 WebSocket 또는 WebSocket 의 MQTT 통합
실시간 애플리케이션을 구축하려면 데이터를 채우는 곳에 접근해야 함
- websocket 과 appsync 를 사용할 수 있음
모바일 애플리케이션이라면 로컬 데이터에 접근하고 데이터 동기화를 원함
- appsync 는 전에 본 cognito sync 라는 서비스를 대체함

appsync 를 시작하면 1개의 GraphQL 스키마를 업로드함
appsync 의 핵심은 업로드한 GraphQL 스키마가 있고 데이터를 가져오는 법을 알려주는 리졸버가 있다는 것
Security
appsync graphQL api 와 애플리케이션이 상호 작용하도록 권한을 주는 4가지 방법
API_KEY - API Gateway 처럼 키를 생성하고 사용자에게 줌
AWS_IAM - IAM 사용자, 역할, 계정에 걸친 접근을 부재 api 에 허용하는 것
OPENID_CONNECT - OpenID Connect 공급자와 JWT 를 통합함
AMAZON_COGNITO_USER_POOL - Cognito 사용자 풀을 통해 생성한 기존 사용자 풀과 통합함
appsync 에서 사용자 정의 도메인과 HTTPS 보안을 원한다면 AppSync 앞에 CloudFront 를 사용할 것을 추천한다고 함
385. AppSync 실습

api 를 생성한다고 함
마법사를 사용해서 생성 - 이벤트 앱을 선택하고 시작

3분~5분 정도 기다려야 한다고 함

graphQL 의 모든 소스인 스키마 부터 본다고 함
자세히 스키마를 알아보진 않지만 여러 type 으로 이루어져있다고 한다

appsync 가 만들어준 2개의 dynamoDB 테이블을 확인할 수 있다
함수는 건너뛴다고 함

쿼리는 api 를 이용하여 어떻게 시작할지를 정의한다고 함
create event 로 2개의 이벤트를 실행시켜줬다
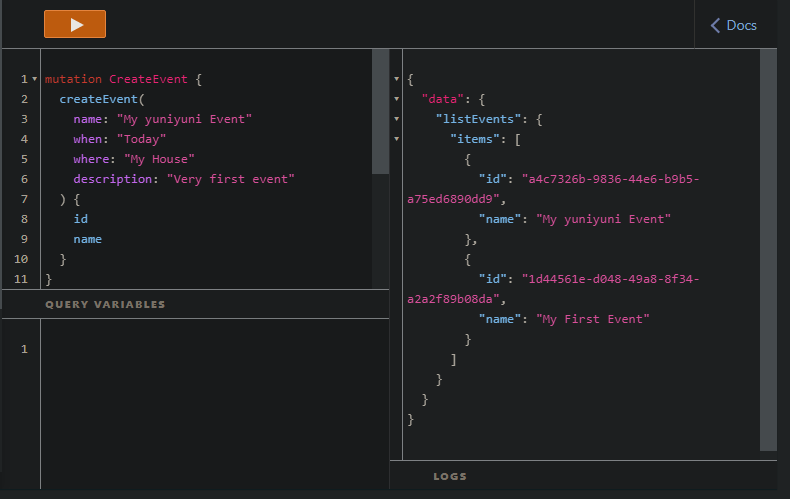
그리고 나서 event table 로 가서 확인해보면

실행한 이벤트들이 생성된것을 확인할 수 있다
appsync api 가 dynamodb 에 직접 데이터를 입력한 것

캐싱은 백엔드에서 쿼리의 숫자를 줄여주는 캐싱 동작이라고 함
전체 요청 캐싱 또는 리졸버 별 캐싱을 사용할 수 있다고 함
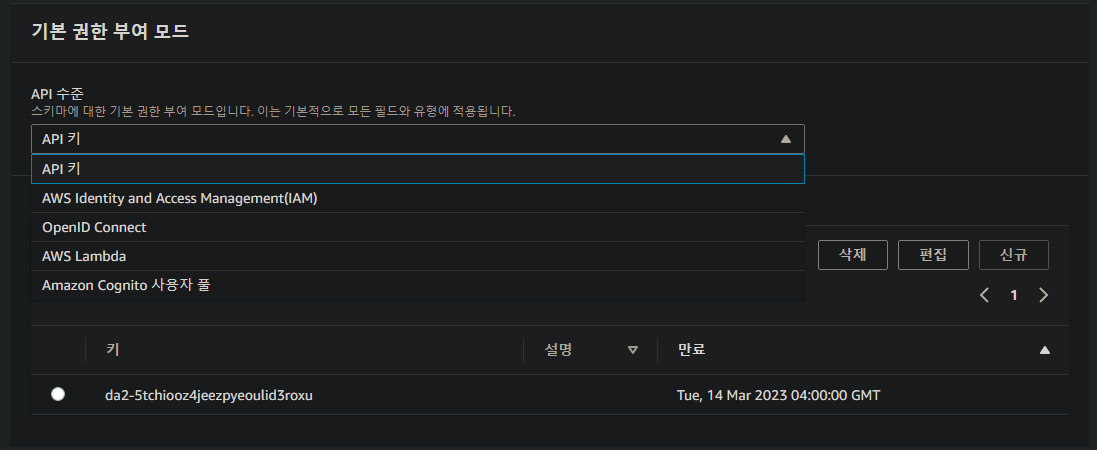
설정에서는 api 를 설정할 수 있다고 함
api key 로 사람들이 이 api 를 사용할 수 있다고 함
api 이름을 공유할 수 있고 기본 권한 모드를 변경할 수 있다고 함
기본 권한 부여 말고도 추가 권한 부여 공급자로 위 5개 방식을 적용할 수 있다고 함
개요만 살펴보고 appsync api 는 삭제해줬다
appsync api 를 삭제해도 dynamoDB 테이블은 삭제되지 않아서 따로 삭제해야한다고 함
386. AWS Amplify
Amplify - 모바일 및 웹 애플리케이션의 생성에 사용하는 서비스
다양한 컴포넌트로 구성되어있음
- Amplify Studio : 프론트엔드 UI 와 백엔드 모두에 풀 스택 앱을 비주얼적으로 빌드하는데에 사용됨
- Amplify CLI : 위와 동일한 역할을 하지만 CLI 로 제공
- Amplify Libraries : 앱과 aws 서비스의 연결을 제공 (Cognito, s3 등)
- Amplify Hosting : Amplify 애플리케이션을 AWS 로 호스팅해주고 빠른 서비스를 제공해줌
AWS Amplify

모바일 및 웹 애플리케이션의 시작을 위한 도구의 모음
모바일 및 웹 애플리케이션을 위한 Elastic Beanstalk 정도
amplify 는 데이터 스토리지, 인증파일 데이터의 보관 및 머신러닝과 같은 필수 기능들을 제공해줌
프론트엔드 라이브러리 또한 제공
신뢰성, 보안 및 확장성에 대한 모범 사례가 통합되어 있음
앱을 배포하는데 있어서 Amplify CLI 혹은 Amplify Studio 가 사용됨
Authentication
amplify add auth (cli) :
amazon cognito 를 활용
사용자 등록, 인증, 복구 등의 기능 제공
MFA, 소셜 로그인 등 지원
프론트엔드에 빌드하고 cognito 통합을 위해 사전 빌드된 컴포넌트가 제공됨
세부적인 인증 제공
Data Store
amplify add api (cli) :
API 에 대해 amazon appsync 를 활용
데이터 스토리지에는 amazon dynamoDB 활용
이 기능을 통해 로컬 데이터로 작업을 한 후 amplify 프레임워크를 활용해 다른 복잡한 코드 없이도 클라우드로 자동 동기화 되게 할 수 있음
GraphQL 과 AppSync 의 전반에 의해 제공되는 기능
오프라인 및 실시간으로 사용 가능
Amplify Studio 를 사용해 데이터의 모델링 또한 가능함
AWS Amplify Hosting

애플리케이션의 배포를 시작할 때 사용하는 기능
amplify add hosting (cli) :
현대적인 웹 앱을 빌드하고 호스팅하도록 해줌
빌드, 테스트 및 배포와 같은 CICD 가능
요청 미리보기를 풀링
사용자 지정 도메인 및 모니터링
리다이렉트와 사용자 지정 헤더 및 비밀번호 보호 설정
Netlify 나 Vercel 등과 유사
387. AWS Amplify 실습


먼저 amplify studio 로 build 해본다고 함
대충 앱 이름을 입력해주고



기다려 준다
amplify cli 를 사용해 amplify 앱을 설정하는 과정도 이와 유사하지만
studio 의 콘솔이 편리하다고 함

amplify 앱 콘솔이ㅏㄷ
설정이나 프론트-백 엔드 작업환경을 제공해준다
studio 로 시작을 눌러놓고 호스팅 환경으로 가보면

소스코드 리포지토리로 연결해 몇 분 안에 이 앱을 웹앱으로 호스팅 할 수 있다고 한다

studio 화면이다
여러 기능들이 있지만 강의에서는 aws 백엔드의 서비스와 통합 하는 부분을 주로 다룬다고 함

manage 의 content 로 가서 data modeling 에서 add model 로 모델을 추가하고 배포해보면

cloudformation 을 통해 새로운 리소스들이 생성되고있고

datastore 테이블과 users 테이블이 생성된 것을 확인할 수 있다

또한 appsync 서비가 만들어져 있고 demoapp-staging 이라는 api 를 받고 있는데
스키마를 확인해보면 모델 추가에서 설정했던 항목들이 type 으로 들어가있고
데이터 원본을 보면 dynamodb 테이블이 연결되어있는걸 확인할 수 있다
데이터 모델이 생성되면 content 에서 create users 작업을 할 수 있다



dynamodb 의 users 테이블에서 아까 생성한 데이터를 확인할 수 있다
manage 의 user management 로 가면 인증 설정을 할 수 있다
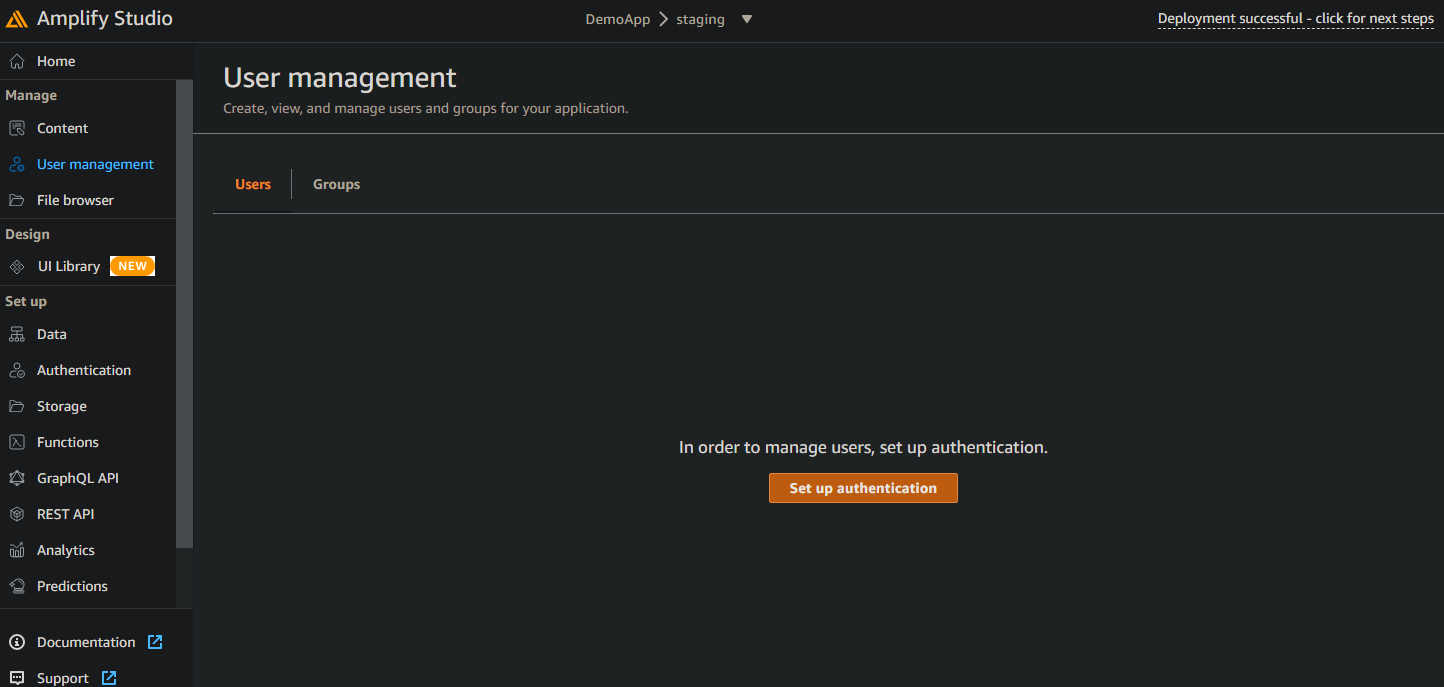
그러면 처음부터 cognito 를 설정하는 start from scratch 옵션과
cognito 를 재사용하는 옵션이 있다

로그인 메커니즘을 정의하고 mfa 를 활성화 시킬 수도 있다
가입 설정에서 세부 조항들을 넣을 수 있고 비밀번호 규칙이나 메일 인증을 활성화 할 수 있다
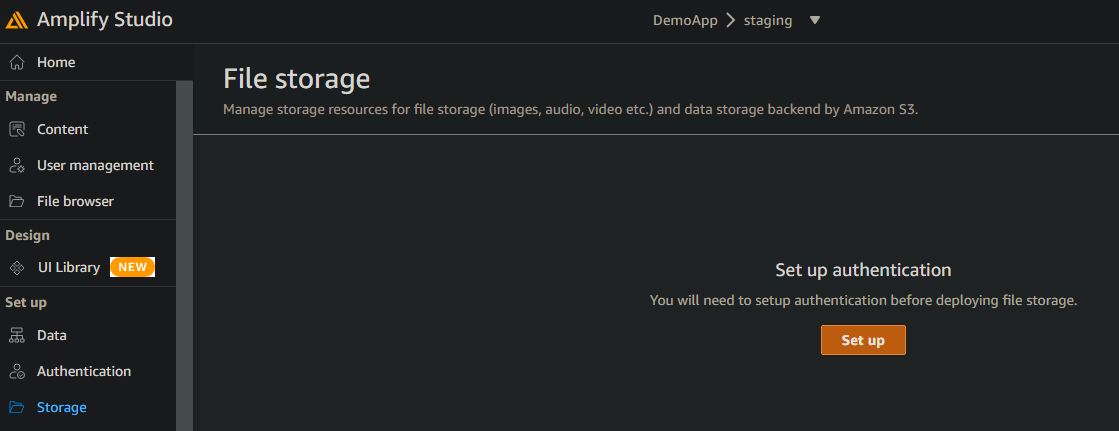
storage 메뉴에서는 amazon s3 에 의해 제공되는 스토리지를 설정할 수 있다
스토리지 기능을 활성화하려면 인증 설정을 마쳐야 한다고 한다

function 에서는 amplify 내에서 직접 람다 함수를 생성할 수 있다고 한다

GraphQL API 는 AppSync

REST API 는 DynamoDB 상의 lambda 함수가 된다고 함

Analytics 메뉴는 데이터를 캡쳐하기 위해 kinesis 나 pinpoint 와 같은 다른 서비스를 사용한다고 함

Predictions 은 머신 러닝을 사용

Interactions 은 aws 서비스로부터의 챗봇 사용

Notifications 은 pinpoint 와 SNS 를 사용한다고 함

UI 라이브러리를 통해 로그인, 버튼, 데이터 상호작용 등 백앤드에 연결된 UI 코드를 프론트앤드 개발에 사용할 수 있다고 함

studio 화면에서 현재 앱에 대해 로드맵을 제공해주는데
데이터 모델은 생성했었
이제 앱 콘텐츠를 수정 및 확인 할 수 있고
로그인 및 가입을 구성한 후에는 UI 를 만들고 배포할 수 있다
실습이 끝나고 amplify 콘솔에서 앱을 삭제해줬다
cloudforamtion stack 이 삭제되기때문에 모두 깔끔하게 정리된다
'AWS > AWS Certified Developer Associate' 카테고리의 다른 글
| [Udemy][day-62,63] Section29 : AWS 보안 및 암호화: KMS, 암호화 SDK, SSM 파라미터 스토어, IAM 및 STS (0) | 2023.03.11 |
|---|---|
| [Udemy][day-61] Section28 : 고급 자격 증명 (0) | 2023.03.07 |
| [Udemy][day-59,60] Section26 : Cognito (0) | 2023.03.02 |
| [Udemy][day-59] Section25 : 클라우드 개발 키트 (Cloud Development Kit, CDK) (0) | 2023.03.02 |
| [Udemy][day-58] Section24 : AWS SAM - 2 (0) | 2023.02.28 |