#AWS Certified Developer Associate
313. DynamoDB 개요
NoSQL databases (비관계형 데이터베이스)
- 분산되기 때문에 수평적 확장성을 가짐
MongoDB, DynamoDB 가 대표적인 NoSQL
NoSQL db 는 join 과 같은 쿼리를 지원하지 않거나 제한적으로 지원함
- 따라서 필요한 모든 데이터는 db에서 한줄(one row)로 표시되어야 함
Amazon DynamoDB 개요
완벽하게 관뢰되는 고가용성의 NoSQL DB 이고 여러 AZ 에 걸쳐 즉시 복제할 수 있다
대규모 워크로드로 확장되고 완벽하게 분산됨
- 즉, 워크로드에 관계 없이 초당 수백만개의 요청, 수조 개의 행과 수백 테라바이트의 스토리지로 확장 가능
- 성능 층면에서 빠르고 일관성이 있음 - low latency on retrieval
IAM 과 완전히 통합됨 - 보안 , 권한 부여 등 관리를 할 수 있음
DynamoDB Streams 로 이벤트 기반 프로그래밍을 활성화 할 수 있음
비용이 저렴하고 오토 스케일링 기능이 있음
다른 스토리지 계층에 대한 Standard & Infrequent Access 테이블 클래스가 있음
DynamoDB - Basics
dynamodb 는 테이블로 구성됨
각 테이블은 기본 키(Primary Key)를 가짐 (must be decided at creation time)
각 테이블은 항목(items)이라고 부르는 행(rows)을 무한대로 가질 수 있음
각 항목들에는 속성이 있음 - 이 속성들은 테이블의 열과 비슷함 (can be added over time - can be null)
각 항목, 행의 데이터의 최대 크기는 400KB 로 제한이 있음
지원되는 데이터 유형
- Scalar Types - String, Number, Binary, Boolean, Null
- Document Types - List, Map
- Set Types - String Set, Number Set, Binary Set (집합)
DynamoDB - Primary Key
option 1 : partition key (hash 전략)
- 파티션 키는 일반적인 db와 유사하게 항목마다 고유해야 함
- 파티션 키는 데이터가 분산될 수 있을 만큼 다양해야 함
- ex) user 테이블에서 사용하는 "user_id"

option 2 : partition key + sort key (hash + range)
- 이 2개 항목의 조합은 항목마다 반드시 고유해야 함
- 데이터는 파티션 키에 의해 그룹화 됨
- ex) users-game 테이블에서 "user_id" 는 파티션 키이고 "game_id" 는 정렬키가 됨

314. DynamoDB 기초 실습
서버리스니까 바로 테이블을 생성해보자

테이블 이름은 Users 로 해줬고 파티션키는 user_id 로 해줬다
지금은 일단 정렬 키는 생략한다고 함
테이블 설정에는 기본 설정과 설정 사용자 지정 옵션이 있는데

기본 설정은 위와 같고
사용자 지정 설정으로 들어가보면

테이블 클래스를 지정할 수 있는데
대부분의 경우 Standard 클래스를 사용하고, 데이터를 오랫동안 사용하지 않거나 읽기 및 쓰기 작업이 많이 이루어지지 않는다면 Standard-IA 를 사용한다고 함
용량 계산기는 추후에 다룬다고 함

온디맨드 모드는 고급 설정이기 때문에 나중에 다룬다고 함
프로비저닝 모드로 설정하고
오토스케일링은 일단 꺼놓고 진행함
총 10개의 단위가 무료로 제공된다고 하는데 각각 2로 설정하고 다음

보조 인덱스는 고급 기능이라 추후 다룬다고 함
아래에서 예상 읽기/쓰기 용량 비용을 산출해 줌
프리티어는 단위 10개까지 무료라고 하지만 프리티어를 벗어났다면 이 수치를 참고할 필요가 있을듯

암호화는 기본값인 dynamodb 소유로 놓고 테이블 생성

아래 항목에 '라이브 항목 수 가져오기' 로 항목(items) 를 사져올 수도 있지만
콘솔 오른쪽 위의 표 항목 탐색 (view items) 를 통해 items 탭으로 들어갈 수 있다

항목 화면에 들어오면 테이블을 스캔하거나 쿼리하는 옵션이 있는데
지금은 그냥 오른쪽 아래 항목 생성으로 아이템을 생성한다고 한다

파티션 키에 값을 입력해주고
새로운 항목 2개를 추가로 생성해주고 값도 입력해줬다
오른쪽에 보이는 여러 속성으로 항목을 구성할 수 있고
오른쪽 위에 보면 양식(form) 혹은 json 형식으로 설정해서 항목을 편집할 수 있다
항목 생성

item 화면으로 돌아오면 item 이 리턴되어있는 것을 확인할 수 있다
아이템을 더 추가해본다고 한다

만약 새로 생성하려는 파티션키의 값이 이미 테이블에 존재한다면 이렇게 에러가 발생한다
새로운 속성인 age 에 나이를 새로 입력하고 항목을 생성해주면

이렇게 자동으로 null 값을 처리해준다
RDS SQL DB 에서는 특정 열이 정의되지 않거나 특정 값이 없다는 등 오류가 나지만
이전에 생성했던 항목인 yeonwoo123 에 자동으로 age 속성에 null 값으로 처리해서 추가할 수 있다
즉 파티션 키인 user_id 만 not null 이면 계속 새로운 속성을 추가할 수 있다
항목을 추가하는 것처럼 테이블을 추가하는 것도 쉽다고 한다
dynamoDB 메인 화면으로 돌아가서 create table 을 클릭해 새로운 테이블을 만든다고 함

사용자의 게시물을 보여주는 테이블을 생성한다고 한다
테이블 이름과 파티션 키를 위와 같이 입력해주고
정렬 키에는 post_ts (timestemp) 로 해준다
테이블 세팅은 사용자 지정으로 들어가주고
스탠다드 클래스 선택
읽기 쓰기 용량은 프로비저닝 됨 으로 선택하고
오토스케일링을 둘다 꺼주고 용량 단위는 각각 2로 설정한 다음 테이블 생성

생성해준 정렬 키가 적용된 것을 확인할 수 있다
이제 아이템을 생성해주기 위해 표 항목 탐색으로 들어가준다

위처럼 파티션키와 정렬키 값을 입력해주고 새로운 속성 하나를 만들어줘서 임의로 입력해준다
2번째 아이템도 생성해주는데

처음으로 생성했던 항목의 파티션키와 같은 값을 입력해주고 정렬키의 날자만 하루 뒤 날자로 해서 생성해주면 문제 없이 생성이 된다

같은 user_id 를 사용해도 post_ts 가 다르기 때문에 아이템 생성이 가능하다
이 조합에서 둘중 하나만 달라도 된다는 뜻
이런 경우엔 파티션 키를 잘 설정해 두어야 한다고 함
계속 반복될 키를 설정해두면 (만약 yeonwoo123 유저가 1만개의 게시물을 혼자 업로드 했다면) 하나의 id 에 데이터가 쏠리게 됨
315. DynamoDB WCU 및 RCU - 처리량
DynamoDB - Read/Write Capacity Modes (읽기 쓰기 용량 모드)
테이블의 용량을 제어하는 방법 - 사전에 읽기/쓰기 처리량을 지정해야 함
- Provisioned Mode (default)
초당 읽기/쓰기를 지정 - 읽기 용량 유닛, 쓰기 용량 유닛
사전에 용량을 계획해야 함
프로비저닝된것에 대해 비용을 지불함
- On-Demand Mode
워크로드에 기반해서 읽기/쓰기를 자동 스케일 업/다운 함
사전에 용량을 계획할 필요가 없음 - 용량 유닛을 프로비저닝 할 필요가 없음
사용한 만큼만 비용을 지불하면 됨 - 프로비저닝 모드보다 훨씬 비쌈
24시간마다 프로비저닝 모드와 온디멘드 모드를 스위칭할 수 있음
R/W Capacity Modes - Provisioned
이 모드에선 읽기/쓰기 용량 유닛을 프로비저닝 해야 함
Read Capacity Units (RCU) - 읽기 처리량 (throughput for reads)
Write Capacity Units (WCU) - 쓰기 처리량 (throughput for writes)
수요를 맞추기 위해 처리량을 오토 스케일링 하는 옵션이 있음 - 목표 처리량 단위 사용 - dynamoDB 가 스케일링
만약 프로비저닝한 것보다 더 많이 소비(RCU/WCU 초과) 할 경우 버스트 용량(Burst Capaciry) 을 일시적으로 사용 가능
- 만약 버스트 용량을 모두 소진하면 '프로비저닝 처리량 초과 예외' (ProvisionedThroughputExceededException) 발생
- 위 예외가 발생하면 작업을 다시 시도해야 하며 이 전략을 지수 백오프 전략(exponential backoff) 라고 함
읽기, 쓰기 용량을 계산하는 문제가 출제될 수 있다고 함
DynamoDB - Write Capacity Unit (WCU)
쓰기 용량 유닛(WCU) 는 '최대 1KB 항목에 대해 초당 1개의 쓰기'를 의미함
항목이 1KB 보다 클 경우 더 많은 WCU 를 사용하게 됨
예시)
초당 항목 10개를 쓰고 항목의 크기는 평균 2KB 이다. 이때 WCU 의 값은?
- 20 WCUs
초당 6개 항목을 쓰고 항목의 크기는 4.5KB 이다. 이때 WCU 의 값은?
- 30 WCUs
분당 120 개의 항목을 쓰고 항목의 크기는 2KB 이다. 이때 WCU 의 값은?
- 4 WCUs
Strongly Consistent Read vs Eventually Consistent Read (dynamoDB 의 2개의 읽기 모드)
강력한 일관된 읽기 모드 vs 최종적 일관된 읽기 모드

dynamoDB 는 서버리스 서비스지만 이면에는 서버가 존재함
데이터가 쓰여지면 내부에서 복제되는데 이를 다시 읽을때 이 읽기 모드가 적용되는데에 차이가 있음
데이터를 쓴 직후 읽어들일때 최종적 일관된 읽기 모드로 데이터를 불러오면 오래된 데이터가 불러질 가능성이 있음
- 아직 다른 서버로 복제 되기 전 읽기 실행 시
위 가능성 배제를 위해 강력한 일관된 읽기 모드를 실행하면 쓰여졌던 데이터를 바로 불러올 수 있음
ConsistentRead 매개변수를 True 로 하면 됨
항상 '강력한 일관된 읽기 모드' 로 설정하지 않는 이유는 RCU 가 2번 발생하게 되고 이에 따라 비용이 증가하게 됨
지연 시간 또한 더 높다
DynamoDB - Read Capacity Units (RCU)
읽기 용량 유닛 - 크기가 최대 4KB 인 항목마다 초당 '강력한 일관된 읽기 1개' 또는 '최종적 읽기 2개' 를 의미함
만약 항목이 4KB 보다 크다면 더 많은 RCU 가 소비됨
예시)
초당 강력한 일관된 읽기 10개가 있고 항목 크기가 4KB 이다. 이때 RCU 값은?
- 10 RCUs
초당 최종적 일관된 읽기가 16개 이고, 항목 크기가 12KB 이다. 이때 RCU 값은?
- 24 RCUs
초당 강력한 일관된 읽기가 10개 이고, 항목의 크기가 6KB 이다. 이때 RCU 값은?
- 20 RCUs
DynamoDB - Partitions Internal
dynamoDB 가 파티션과 함께 백엔드에서 작동하는 법
dynamoDB 는 테이블로 이루어져 있고 각 테이블에는 파티션이 있음
파티션은 데이터의 복사본으로 특정 서버에 있음
모든 데이터는 해싱 알고리즘을 통과함 - 즉, 파티션 키 만이 해싱 알고리즘을 통해 어느 파티션으로 이동해야 하는지 알 수 있음

파티션 갯수 = (RCU/3000) + (WCU/1000)
데이터 양 = Total size/10GB
위 두가지 중 최댓값이 파티션의 갯수
DynamoDB - Throttling (조절)
파티션 수준에서 RCU 와 WCU 를 초과할 때 프로비저닝 처리량 초과 예외(ProvisionedThroughputExceededException)가 발생
예외 사유
Hot Keys - 하나의 파티션 키가 인기 있는 항목이여서 특정 파티션으로부터 너무 많이 읽혔을 때
Hot Partitions
너무 큰 항목 - WCU 와 RCU 가 계산될 때 항목에 크기에 따라 달라지기 때문
예외 해결
예외가 발생했을때 지수 백오프(Exponential backoff) 를 진행 (SDK 를 사용한다면 이미 포함된 사항임)
파티션 키를 최대한 많이 분산시켜야 함 (예방 차원)
만약 RCU issue 라면 DynamoDB Accelerator(DAX) 라는 기능을 사용
R/W Capacity Modes - On-Demand
어떤 읽기와 쓰기든 자동으로 승인하여 워크로드에 따라 스케일 업/다운 함
용량을 따로 계획할 필요가 없음
무제한 WCU & RCU, 조절(throttle) 없음, 훨씬 비쌈
실제로 사용한 읽기와 쓰기에 비용이 청구됨 (ReadRequestUnit, WriteRequestUnit)
온디맨드 모드는 프로비저닝 용량 모드보다 약 2.5배 더 비쌈
애플리케이션 워크로드를 잘 모르거나, 애플리케이션 트래픽이 예측 되지 않을 때 사용 권장
316. DynamoDB WCU 및 RCU 실습

테이블 화면의 추가 설정으로 가면 읽기/쓰기 용량을 편집할 수 있다
dynamoDB 는 필요한 경우 용량 모드를 변경할 수 있다

실제 환경에서 온-디멘드 모드를 설정한다고 한다면
만약 24시간 내내 테이블을 사용하지 않거나 하루에 한시간 정도만 테이블을 많이 사용할 때 적합한 용량 모드라고 함
프로비저닝 모드를 활성화하면 요금 계산기를 이용할 수 있다
일관성 항목에 트랜잭션이라는 옵션도 존재하지만 나중에 설명한다고 한다

dynamoDB 의 테이블 용량 오토스케일링은 매우 편리한데
애플리케이션의 최소, 최대, 목표 사용량만을 생각하면 모두 서비스가 처리해준다

(2.8 끝)
(2.10 시작)
317. DynamoDB 기본 API
writing data
- PutItem
PutItem 을 사용하면 동일한 개인 키를 가진 새 항목을 생성하거나 전체 대체됨
WCU 를 소비함
- UpdateItem
기존 항목 속성을 수정하거나 속성이 없는 경우는 새 항목을 추가함
다른 전체 속성이 아니라 일부 속성만 수정하는 것
원자성 카운터(Atomic Counters) 와 함께 사용할 수 있음
- Conditional Writes
조건이 충족되면 쓰기, 업데이트, 삭제만 허용, 항목에 관한 동시 액세스 지원
reading data
- GetItem
기본 키를 기반으로 데이터를 읽음
개인 키는 HASH 이거나 HASH+RANGE 임
두가지 읽기 모드
- 최종적 일관된 읽기 모드 (Eventually Consistent Read) (default)
- 강력한 일관된 읽기 모드 (Strongly Consistent Read) (more RCU - might take longer)
ProjectionExpression 식 도 api 에서 지정할 수 있음 - 이 프로젝션 식은 dynamoDB 에서 몇가지 속성만 수신하도록 함
reading data (Query)
쿼리는 파티션 키인 KeyConditionExpression 을 기반으로 리턴됨
FilterExpression (필터 표현식)
- 이는 쿼리 작업 후에 추가 필터링을 추가하는 것이지만 데이터가 반환되기 이전이 되야 함
- 키 속성과 함께 사용됨
쿼리가 리턴 하는 것
항목 리스트 - 쿼리 매개 변수 제한을 기반해 검색 항목 수에 제한이 있음
1MB 제한
만약 제한보다 더 많은 데이터 반환이 필요하다면 결과를 페이지 매김(pagination) 해서 더 요청할 수 있음
테이블, 로컬 보조 인덱스, 글로벌 보조 인덱스를 쿼리할 수 있음
reading data (Scan)
GetItem 은 항목별 하나였고, 쿼리는 특정 파티션 키나 정렬 키였음
스캔 항목은 전체 테이블을 읽는 것, 데이터를 필터링 할 수 있음 (비효율적)
스캔은 전체 테이블을 내보내며 각 스캔은 최대 1MB 의 데이터를 반환함 - 계속 읽으려면 페이지 매김(pagination) 을 사용
많은 RCU 소비
일반 작업에 영향을 미치지 않으려면 제한 문장을 사용해서 스캔에 영항을 주거나 결과의 크리를 줄이고 잠시 멈추는 방법 사용
많은 RCU 를 사용하더라도 가능한 한 빨리 스캔하려면 병렬 스캔(Parallel Scan) 사용 가능
스캔은 프로젝션 식(ProjectionExpression) 이나 필터 표현식 (FilterExpression) 과 함께 사용 가능
- 프로젝션 식은 특정 속성만 검색함
- 필터 표현식은 클라이언트 측면을 수정함
deleting Data
- DeleteItem
개별 항목 삭제에 사용
조건부 삭제도 가능 (비용이 없는 항목만 삭제)
- DeleteTable
전체 테이블과 항목을 삭제
스캔을 사용하는 것보다 빠름
Batch Operations
api 호출 수를 줄여 배치 작업을 할 수 있음
효율적인 작업을 위해 병렬로 작업함
일부 배치가 실패할 수 있는데 이 경우 해당 항목을 다시 시도해야 함
- BatchWriteItem
최대 15번의 PutItem 을 얻거나 한 번의 호출로 DeleteItem 을 실행함
항목 당 400KB 의 데이터로 최대 16MB 의 데이터를 작성할 수 있음
항목은 따로 업데이트 할 수 없음 - UpdateItem api 를 사용할 수는 있지만 BatchUpdate 는 실행할 수 없음
- BatchGetItem
한 번에 하나 이상의 테이블에서 항목을 읽음
최대 16MB 의 데이터에서 최대 100개의 항목을 읽을 수 있음
지연 시간 최소화를 위해 항목이 병렬로 검색됨
318. DynamoDB 기본 API 실습


metrics 를 살펴보면 api 가 호출되었던 내용들을 모두 확인할 수 있다
319. DynamoDB 인덱스 (GSI + LSI)
Local Secondary Index (LSI) - 로컬 보조 인덱스
LSI 는 테이블에 대체 정렬 키를 제공함
- 기본 테이블에 동일한 파티션 키를 가지지만 추가적으로 정렬 키를 얻는 것
이 정렬 키는 하나의 스칼라 속성으로 구성됨 (문자열, 숫자, 2진수 등)
테이블 당 최대 5개의 LSI 를 얻을 수 있음
LSI 는 반드시 테이블 생성 시점에 정의 되어야 함
메인 테이블로부터 일부 또는 전체 속성을 얻을 수 있음

Global Secondary Index (GSI) - 글로벌 보조 인덱스
GSI 는 대채 기본 키 (Alternative Primary Key - HASH or HASH + RANGE) 를 제공함
테이블 내에 키 속성이 아닌 항목의 쿼리 속도를 높이는데 유용함
인덱스는 스칼라 속성(숫자, 문자열, 2진수) 로 구성되어 있음
인덱스에서 프로젝션할 속성을 지정할 수 있음
이 인덱스는 새로운 테이블의 개념으로 반드시 RCU 와 WCU 를 프로비저닝 해야 함
GSI 는 테이블 생성 후에도 추가나 생성이 가능함

Indexes and Throttling
GSI
- 쓰기가 GSI 에서 쓰로틀 되면 메인 테이블도 스로틀 됨
- 메인 테이블에서 WCU 에 아무 문제가 없어도 GSI 에서 제한이 있으면 메인 테이블도 제한됨
- 그래서 GSI 와 파티션 키를 신중하게 선택해야 함
- WCU 용량도 신중하게 할당 해야 함
LSI
- 메인 테이블의 WCU 와 RCU 를 사용함
- 특별하게 스로틀을 고려할 필요가 없음
320. DynamoDB 인덱스 (GSI + LSI) - 실습
테이블을 새로 만들어 준다
이름은 demo_indexes
파티션 키는 user_id, 정렬 키는 game_ts 로 하고
RCU 와 WCU 는 각각 1로 프로비저닝 해줬다
이후 로컬 보조 인덱스를 생성

테이블 생성 화면에서 보조 인덱스 탭에서 생성할 수 있다
로컬 인덱스는 테이블 생성 시에만 생성할 수 있다

속성 프로젝션을 선택할 수 있는데 지금은 all 로 해놓고 인덱스를 생성
테이블 생성
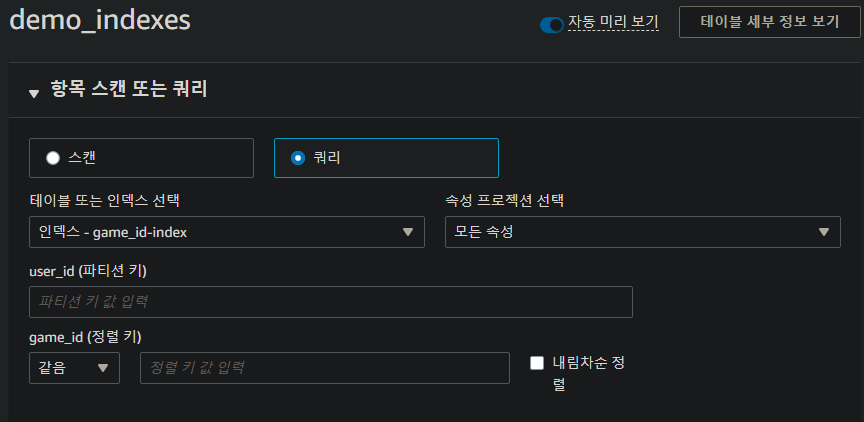
쿼리 시 만들었던 로컬 보조 인덱스로 쿼리할 수 있다
테이블의 인덱스 탭에 들어가보면

위처럼 gsi 와 lsi 를 확인할 수 있다
gsi 는 테이블 생성 후에도 생성할 수 있기 때문에 지금 생성해주려고 한다

파티션키를 새로 생성할 수 있고
정렬키를 선택적할 수 있다

읽기/쓰기 용량을 따로 설정해줘야 하며 추가 요금이 발생한다고 한다
프로젝션은 all 로 하고 인덱스 생성
만약 gsi 를 많이 쿼리하거나 쓰기에 스로틀 되면 메인테이블도 스로틀 된다
반면 LSI 는 메인 테이블의 RCU 와 WCU 를 사용한다

gsi 는 생성에 수분 소요된다
'AWS > AWS Certified Developer Associate' 카테고리의 다른 글
| [Udemy][day-53] Section22 : AWS 서버리스 : DynamoDB - 3 (0) | 2023.02.13 |
|---|---|
| [Udemy][day-52,53] Section22 : AWS 서버리스 : DynamoDB - 2 (0) | 2023.02.11 |
| [Udemy][day-49] Section21 : AWS 서버리스 : Lambda - 3 (0) | 2023.01.15 |
| [Udemy][day-48] Section21 : AWS 서버리스 : Lambda - 2 (0) | 2023.01.13 |
| [Udemy][day-47] Section21 : AWS 서버리스 : Lambda - 1 (0) | 2023.01.11 |