- 텐서플로우 예제 (이미지 분류)
이미지 분류 | TensorFlow Core
이 튜토리얼은 꽃 이미지를 분류하는 방법을 보여줍니다. keras.Sequential 모델을 사용하여 이미지 분류자를 만들고 preprocessing.image_dataset_from_directory를 사용하여 데이터를 로드합니다. 이를 통해 다
www.tensorflow.org
저번에 한거에서 이어서 해보겠다.
|
1
2
3
4
|
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
|
cs |
여기서 pathlib 모듈의 기본 아이디어는 파일 시스템 경로를 단순한 문자열이 아니라 객체로 다루는 것이다.
https://brownbears.tistory.com/415
[Python] pathlib 사용하기
파이썬 3.4부터 내장함수로 pathlib가 추가되었습니다. pathlib가 추가되기 이전에는 os 모듈을 사용했습니다. pathlib는 파일위치 찾기, 파일 입출력과 같은 동작을 하는데 os모듈과 어떻게 다른지 아
brownbears.tistory.com
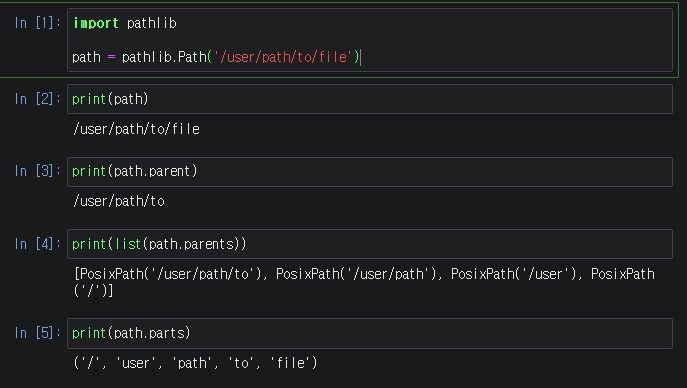
그러니까 위 코드를 보면 2번행에서 해당 url 에서 압축파일을 받고, 3번행에서 압축을 해제하는 작업인 것 같고, 4번행에서 data_dir 의 경로를 지정해준것 같다.
|
1
2
3
4
5
6
7
8
9
10
11
|
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
#다운로드 후, 데이터세트 사본을 사용할 수 있습니다. 총 3,670개의 이미지가 있습니다.
"""
glob()은 많은 파일을 다룰때 사용자가 제시한 조건에 맞는
파일명을 리스트 형식으로 반환해준다.
'*'은 임의 길이의 모든 문자열을 의미하고
'?'는 한자리 문자를 의미한다.
위 코드라면 .jpg로 끝나고 '문자열/문자열'형태의 파일을 리스트 형식으로 반환해
그 리스트의 길이(인수의 개수)를 출력하는 코드인듯
"""
|
cs |
glob() 은 유용하게 쓰일듯 하다.
|
1
2
|
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))
|
cs |
roses 에다가 list로 glob 한 파일들을 넣어서, PIL.Image.open 으로 파일을 여는것같다.
사진들을 리스트안에 넣어서 활용하는것 같다.
이제 데이터셋을 만드는것 같은데 이해가 잘 안된다.


훈련에 이미지의 80%를 사용하고 검증에 20%를 사용한다고 하는데 무슨소리지...
batch size 는 전체 트레이닝 데이터 셋을 여러 작은 그룹을 나누었을 때 batch size는 하나의 소그룹에 속하는 데이터 수를 의미합니다.
그렇군
height 랑 width 는 높이 넓이 인것 같고

디스크에 로드하는 그런거 같은데... 밑에는 뭘 뜻하는지 모르겠다.
데이터셋을 만들고 모델을 만든 후 머신러닝이 들어가야할텐데... 데이터셋이 뭔지 모델이 뭔지조차 모르겠다.
- 특정 픽셀의 RGB값 출력하고 전역변수에 저장하기
https://codesample-factory.tistory.com/2193
파이썬 PIL을 사용하여 픽셀의 RGB 얻기
PIL을 사용하여 픽셀의 RGB 색상을 얻을 수 있습니까? 이 코드를 사용하고 있습니다. im = Image.open("image.gif") pix = im.load() print(pix[1,1]) 그러나 3 개의 숫자 (예 : R, G의 경우 60,60,60 )가 아닌 숫..
codesample-factory.tistory.com
우선 아주 기본적으로 픽셀의 rgb값을 얻을 수 있는 코드를 발견했다.
|
1
2
3
4
5
6
7
8
|
import numpy as np
from PIL import Image
im = Image.open('fitting_pic.jpg')
rgb_im = im.convert('RGB')
r, g, b = rgb_im.getpixel((72, 49))
print(r, g, b)
|
cs |
그림판에서 찍어봤던 rgb값이 잘 나오는 것을 확인했다.
rgb 값을 변수에 저장까지 하는 법을 알았으니까, 데이터셋으로 이미지를 불러오는건 다음에 생각하고, 300*500 이미지 파일을 만들어서 상의의 픽셀좌표값들의 평균을 출력하도록 만들어보자!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import numpy as np
from PIL import Image
im = Image.open('1.jpg')
rgb_im = im.convert('RGB')
r_list = []
g_list = []
b_list = []
r_list = [0]*8
g_list = [0]*8
b_list = [0]*8
r_list[0], g_list[0], b_list[0] = rgb_im.getpixel((4, 11))
r_list[1], g_list[1], b_list[1] = rgb_im.getpixel((16, 17))
r_list[2], g_list[2], b_list[2] = rgb_im.getpixel((32, 8))
r_list[3], g_list[3], b_list[3] = rgb_im.getpixel((42, 8))
r_list[4], g_list[4], b_list[4] = rgb_im.getpixel((17, 24))
r_list[5], g_list[5], b_list[5] = rgb_im.getpixel((32, 24))
r_list[6], g_list[6], b_list[6] = rgb_im.getpixel((17, 34))
r_list[7], g_list[7], b_list[7] = rgb_im.getpixel((32, 34))
r_AVG = sum(r_list, 0.0) / len(r_list)
g_AVG = sum(g_list, 0.0) / len(g_list)
b_AVG = sum(b_list, 0.0) / len(b_list)
print('R:'+ str(r_AVG) + ' G:' + str(g_AVG) + ' B:' + str(b_AVG))
|
cs |
어찌어찌해서 이렇게 짜봤는데
결과는 조금 상이하게 나온다...
우선 사진은 50*150 의 크기로 넣었다.
다른 피팅모델 사진들도 해당 크기로 수정해야 할것이다.
- 다중 선형 회귀 분석을 적용하는데 이때 y 값에는, 바지 부분의 픽셀 좌표 값의 r,g,b 각각의 평균값을 대표값으로 입력받고 그 일련번호를 반환해 y값에 넣는다.
- 쇼핑몰에서 사진을 100장을 구하여 50*150 으로 자르고 픽셀 좌표에 맞춰서 사진을 옮긴다.
- 많은 이미지를 불러오기 위해 데이터 셋을 만든다.
- 머신러닝을 위한 모델을 만들고 돌려본다
앞으로 4단계면 결과값을 볼 수 있겠다!
하지만 이게 성공한다고 해도 할게 너무나도 많이남았다...
'파이썬 > 공개SW 프로젝트' 카테고리의 다른 글
| [공개SW - 메이킹 로그_14] 도움! (0) | 2021.08.29 |
|---|---|
| [공개SW - 메이킹 로그_13] 데이터셋 만들기 (0) | 2021.08.27 |
| [공개SW - 메이킹 로그_11] RGB의 대표값 만들기 + 텐서플로우 예제(이미지분류) (0) | 2021.08.22 |
| [공개SW - 메이킹 로그_10] 다중 선형 회귀 분석 예제 (0) | 2021.08.21 |
| [공개SW - 메이킹 로그_9] 한줄한줄 다 오류 ㄹㅇㅋㅋ (0) | 2021.08.19 |